Foram encontradas 50 questões.
Disciplina: TI - Desenvolvimento de Sistemas
Banca: CESPE / CEBRASPE
Orgão: SEBRAE
Provas
Disciplina: TI - Desenvolvimento de Sistemas
Banca: CESPE / CEBRASPE
Orgão: SEBRAE
Provas
Disciplina: TI - Desenvolvimento de Sistemas
Banca: CESPE / CEBRASPE
Orgão: SEBRAE
Em aprendizado de máquina, especialmente em algoritmos de árvores de decisão, é fundamental avaliar como os dados são organizados e classificados em diferentes níveis da árvore. Três conceitos-chave que auxiliam na construção e otimização dessas árvores são o gini impurity, a entropy e o information gain. A respeito desses conceitos, julgue os itens a seguir.
I Gini impurity mede a redução da entropy após a divisão de um conjunto de dados com base em um atributo.
II Entropy mede a quantidade de incerteza ou impureza no conjunto de dados.
III Information gain mede a probabilidade de uma nova instância ser classificada incorretamente, com base na distribuição de classes no conjunto de dados.
Assinale a opção correta.
Provas
Disciplina: TI - Desenvolvimento de Sistemas
Banca: CESPE / CEBRASPE
Orgão: SEBRAE
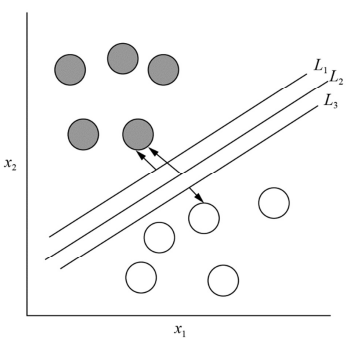
Considerando a figura precedente, assinale a opção correta em relação ao algoritmo de SVM (support vector machine).
Provas
Disciplina: TI - Desenvolvimento de Sistemas
Banca: CESPE / CEBRASPE
Orgão: SEBRAE
O seguinte código Python utiliza o algoritmo KNN
(k-nearest neighbors) para classificação, em que o parâmetro ![]() define o número de vizinhos que o classificador
KNN irá considerar para realizar a previsão.
define o número de vizinhos que o classificador
KNN irá considerar para realizar a previsão.

Com base no código precedente, é correto afirmar que, caso o
valor de ![]() fosse alterado de 3 para 4, o modelo
fosse alterado de 3 para 4, o modelo
Provas
10 ± 4 representa a estimativa intervalar de 95% de confiança para a média de uma população normal, tendo sido obtida a partir de uma amostra aleatória de tamanho n . Para a obtenção dessa estimativa, considerou-se que a variância populacional fosse conhecida. Em novo levantamento feito sobre essa mesma população, mas, dessa vez, tendo-se quadruplicado o tamanho da amostra (4n), foi obtida média amostral igual a 8.
Nesse caso, se 8 ± ε representar a nova estimativa intervalar de 95% de confiança para a média dessa população, é correto afirmar que ε deverá ser igual a
Provas
- Distribuições de ProbabilidadeDistribuições DiscretasBinomial
- Estatística InferencialEstimadoresEstimadores de Máxima Verossimilhança
O conjunto de dados {0, 4, 3, 3, 0} é uma realização de uma amostra aleatória simples retirada de uma população binomial com parâmetros n e p, sendo n = 4 e p uma probabilidade desconhecida.
Com base nessas informações, é correto afirmar que a estimativa de máxima verossimilhança para a probabilidade de ocorrência do valor 2 na população em questão é igual a
Provas
- Estatística InferencialVariáveis AleatóriasVariável Aleatória Discreta
- Estatística InferencialVariáveis AleatóriasVariável Aleatória Multidimensional
- Probabilidades
Se N for uma variável aleatória que siga uma distribuição normal
com média igual a 10 e desvio padrão igual a 5 e se Z =![]() , então a probabilidade de ocorrência do evento “Z = 1,96” será
igual a
, então a probabilidade de ocorrência do evento “Z = 1,96” será
igual a
Provas
- Distribuições de Probabilidade
- Estatística InferencialVariáveis AleatóriasVariável Aleatória Discreta
- Estatística InferencialVariáveis AleatóriasVariável Aleatória Contínua
- Estatística InferencialVariáveis AleatóriasVariável Aleatória Multidimensional
- Probabilidades
Supondo-se que a variável aleatória X possa assumir valores 0, 1,
2 ou 3 conforme a função de distribuição de probabilidade P(X = h) = ![]() na qual h ∈ {0, 1, 2, 3}, é correto
afirmar que o valor esperado de X seja igual a
na qual h ∈ {0, 1, 2, 3}, é correto
afirmar que o valor esperado de X seja igual a
Provas
Um modelo de regressão linear múltipla com dez coeficientes foi ajustado pelo método de mínimos quadrados ordinários, tendo produzido um coeficiente de determinação (R2) igual a 80%.
Nessa hipótese, caso o tamanho da amostra utilizado para esse ajuste tenha sido igual a 46, então o valor correspondente do coeficiente conhecido como “R2 ajustado” deve ter sido igual a
Provas
Caderno Container