Foram encontradas 70 questões.
A linguagem Python oferece um amplo conjunto de bibliotecas
para visualização de dados, permitindo que os analistas da ALEGO
usem-nas em projetos de ciência de dados e transformem dados
em representações gráficas. Diversas bibliotecas atendem a
diferentes necessidades de visualização, desde gráficos estáticos
básicos até painéis interativos sofisticados.
Assinale a alternativa que não corresponde a uma biblioteca para visualização de dados.
Assinale a alternativa que não corresponde a uma biblioteca para visualização de dados.
Provas
Questão presente nas seguintes provas
- Fundamentos de ProgramaçãoAlgoritmosConceitos Básicos de Algoritmos
- Fundamentos de ProgramaçãoTipos de Dados
Um analista precisa calcular o tempo, em número de dias, de
duração dos cursos que os servidores da ALEGO participaram
recentemente. Ele fez um programa em Python (versão 3) e
embutiu no código dados sobre as matrículas do servidor e as
datas de início de conclusão de curso. Analise o código a seguir.

A estrutura utilizada na variável dados_ficticios para armazenar os dados que são tratados pelo programa é conhecido como
A estrutura utilizada na variável dados_ficticios para armazenar os dados que são tratados pelo programa é conhecido como
Provas
Questão presente nas seguintes provas
Uma matriz de confusão resume o desempenho da classificação
realizada por um classificador em relação a alguns dados de
teste. Um caso especial da matriz de confusão é
frequentemente utilizado com apenas duas classes, uma
designada como classe positiva e a outra classe negativa. Nesse
contexto, as quatro células da matriz são designadas como
verdadeiros positivos (VP), falsos positivos (FP), verdadeiros
negativos (VN) e falsos negativos (FN), conforme indicado na
tabela a seguir
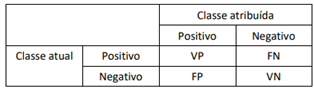
Com relação ao cálculo das medidas de desempenho, analise as afirmativas a seguir.
I. A medida da especificidade (também conhecido por Taxa de verdadeiros negativos) pode ser alcançada através da fórmula: Especificidade = VN / (VN + FP).
II. A medida da sensibilidade (também conhecido por Taxa de verdadeiros positivos ou Recall) pode ser alcançada através da fórmula: Recall = VP / (VP + FN).
III. O valor preditivo positivo (também conhecido como Precisão) pode ser alcançada através da fórmula: Precisão = VN / (VN + FN)
IV. Por fim, O valor preditivo negativo (VPN) pode ser alcançada através da fórmula: VPN = VP / (VP + FP).
Está correto o que se afirma em
Com relação ao cálculo das medidas de desempenho, analise as afirmativas a seguir.
I. A medida da especificidade (também conhecido por Taxa de verdadeiros negativos) pode ser alcançada através da fórmula: Especificidade = VN / (VN + FP).
II. A medida da sensibilidade (também conhecido por Taxa de verdadeiros positivos ou Recall) pode ser alcançada através da fórmula: Recall = VP / (VP + FN).
III. O valor preditivo positivo (também conhecido como Precisão) pode ser alcançada através da fórmula: Precisão = VN / (VN + FN)
IV. Por fim, O valor preditivo negativo (VPN) pode ser alcançada através da fórmula: VPN = VP / (VP + FP).
Está correto o que se afirma em
Provas
Questão presente nas seguintes provas
Matheus foi empossado recentemente pela ALEGO como analista
e está se aprofundando nos estudos das redes neurais (RN). Ele
sabe que as RN podem ter diversas formas de aprendizagem não
supervisionada.
O tipo de aprendizado onde os neurônios de saída da rede disputam entre si para se tornarem ativos e somente um neurônio de saída é ativado em determinado instante se denomina:
O tipo de aprendizado onde os neurônios de saída da rede disputam entre si para se tornarem ativos e somente um neurônio de saída é ativado em determinado instante se denomina:
Provas
Questão presente nas seguintes provas
O perceptron é um dos modelos de redes neurais artificiais mais
simples e tradicionais. A figura a seguir ilustra o grafo arquitetural
de um perceptron. Analise-a.
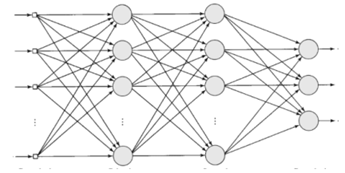
Com relação as características do grafo, analise as afirmativas a seguir.
I. A rede possui várias camadas, sendo quatro camadas ocultas e três camadas de saída de dados.
II. A rede é do tipo totalmente conectada, isso significa que cada neurônio em qualquer camada está conectado a todos os outros neurônios da camada anterior.
III. O fluxo de sinais é unidirecional e progride na rede da esquerda para a direita e de camada em camada.
Está correto o que se afirma em
Com relação as características do grafo, analise as afirmativas a seguir.
I. A rede possui várias camadas, sendo quatro camadas ocultas e três camadas de saída de dados.
II. A rede é do tipo totalmente conectada, isso significa que cada neurônio em qualquer camada está conectado a todos os outros neurônios da camada anterior.
III. O fluxo de sinais é unidirecional e progride na rede da esquerda para a direita e de camada em camada.
Está correto o que se afirma em
Provas
Questão presente nas seguintes provas
Árvores de decisão (AD) são classificadores muito utilizados em
Ciência de Dados. Com relação as características da AD, analise as
afirmativas a seguir.
I. É a representação de uma função que mapeia um vetor de valores de atributos para um único valor de saída.
II. Uma árvore de decisão chega à sua decisão realizando uma sequência de testes, começando por uma de suas raízes e seguindo o ramo apropriado até que uma folha seja alcançada.
III. Cada nó interno na árvore corresponde a um teste do valor de um dos atributos de entrada, os ramos a partir do nó são rotulados com os possíveis valores do atributo, e os nós folha especificam qual valor deve ser retornado pela função.
Está correto o que se afirma em
I. É a representação de uma função que mapeia um vetor de valores de atributos para um único valor de saída.
II. Uma árvore de decisão chega à sua decisão realizando uma sequência de testes, começando por uma de suas raízes e seguindo o ramo apropriado até que uma folha seja alcançada.
III. Cada nó interno na árvore corresponde a um teste do valor de um dos atributos de entrada, os ramos a partir do nó são rotulados com os possíveis valores do atributo, e os nós folha especificam qual valor deve ser retornado pela função.
Está correto o que se afirma em
Provas
Questão presente nas seguintes provas
O algoritmo k-Nearest Neighbors (KNN) baseia-se
fundamentalmente em calcular a distância entre o novo ponto e
todos os pontos de dados do conjunto de treinamento. As medidas
de distância do KNN definem quão “próximos” ou “semelhantes”
dois pontos são no espaço de recursos. Analise a fórmula da
distância de Minkowski
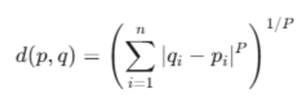
Com relação a derivação da fórmula da distância de Minkowski, analise as afirmativas a seguir.
I. Se P = 2, a fórmula calculará a distância Euclidiana.
II. Se P = 1, a fórmula calculará a distância de Manhattan.
III. Se P = 0, a fórmula calculará a distância Hamming.
Está correto o que se afirma em
Com relação a derivação da fórmula da distância de Minkowski, analise as afirmativas a seguir.
I. Se P = 2, a fórmula calculará a distância Euclidiana.
II. Se P = 1, a fórmula calculará a distância de Manhattan.
III. Se P = 0, a fórmula calculará a distância Hamming.
Está correto o que se afirma em
Provas
Questão presente nas seguintes provas
Janaina, uma analista da ALEGO, desenvolveu o programa Python
(versão 3) que utiliza as bibliotecas numpy (2.0.2) e scikit-learn
(versão 1.6.1) para realizar uma análise de agrupamentos. Analise
o código a seguir.

O resultado impresso é igual a
O resultado impresso é igual a
Provas
Questão presente nas seguintes provas
A regressão logística é um modelo muito popular na ciência de
dados, ele é muito utilizado em diversos projetos da ALEGO. Com
relação às características da regressão logística, analise as
afirmativas a seguir.
I. É um modelo de regressão linear e dentro do contexto do aprendizado de máquina, a regressão logística pertence à família de modelos de aprendizado de máquina supervisionado.
II. Representa dois grupos de interesse como uma variável binária com valores 0 e 1, não importando qual o grupo é designado com os valores o versus 1, mas a designação de como dever ser observada interpretação dos coeficientes.
III. A função logística é representada pelas seguintes fórmulas:
a) Logit(pi) = 1/(1+ ln(-pi))
b) exp(pi/(1-pi)) = β_0 + β _1*X_1 + … + β _k*K_k.
onde:
logit(pi) é a variável dependente ou de resposta, e x é a variável independente.
Está correto o que se afirma em
I. É um modelo de regressão linear e dentro do contexto do aprendizado de máquina, a regressão logística pertence à família de modelos de aprendizado de máquina supervisionado.
II. Representa dois grupos de interesse como uma variável binária com valores 0 e 1, não importando qual o grupo é designado com os valores o versus 1, mas a designação de como dever ser observada interpretação dos coeficientes.
III. A função logística é representada pelas seguintes fórmulas:
a) Logit(pi) = 1/(1+ ln(-pi))
b) exp(pi/(1-pi)) = β_0 + β _1*X_1 + … + β _k*K_k.
onde:
logit(pi) é a variável dependente ou de resposta, e x é a variável independente.
Está correto o que se afirma em
Provas
Questão presente nas seguintes provas
A biblioteca scikit-learn (versão 1.7.2) do Python (versão 3) oferece
uma classe que implementa a regressão logística. Seleciona a
alternativa que apresenta a sintaxe correta dessa classe.
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container