Foram encontradas 2.975 questões.
Uma pesquisa foi realizada para avaliar a percepção dos eleitores a respeito de certo assunto em determinada cidade. Essa cidade possui 20 zonas eleitorais, que, em função de padrões socioeconômicos, foram classificadas em grupos A, B e C. Foram identificadas duas zonas no grupo A, 8 zonas no grupo B e 10 zonas no grupo C. Estudo anterior mostrou que a variabilidade das percepções dos eleitores dentro de cada grupo é significativamente menor que a variabilidade total. Para a seleção da amostra, foi estabelecido o seguinte plano:
► etapa I – de cada grupo, uma zona eleitoral é selecionada ao acaso;
► etapa II – de cada zona eleitoral selecionada, uma amostra aleatória simples de n eleitores é retirada;
► etapa III – cada eleitor i selecionado da zona j (i = 1, ..., n e j = 1, 2, 3) responde a um questionário. A partir das respostas desse eleitor, é calculada uma estatística Xij que mede a percepção desse eleitor sobre o assunto.
Por simplicidade, considera-se que o número de eleitores cadastrados em cada zona eleitoral seja grande o suficiente para a utilização de técnicas para amostras em grandes populações. Considera-se, também, que X1j, ..., Xnj seja uma amostra aleatória simples, retirada de uma população j, com distribuição normal com média θj e variância 1.
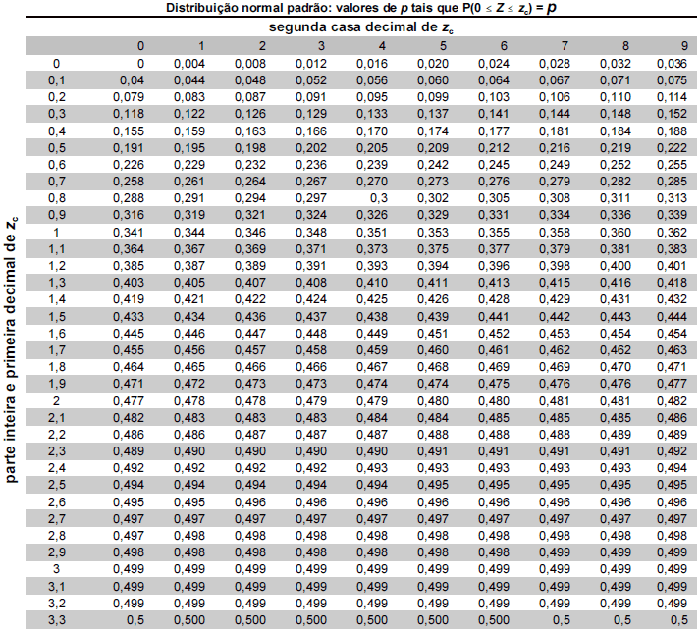
Tabela gerada pela função DIST.NORMP() do Excel.
A respeito da situação descrita no texto e com o auxílio da tabela normal padrão, julgue o item a seguir.
O processo de seleção da amostra descrito na etapa I é conhecido como amostragem por conglomerados.
Provas
| T * 1(n)d | T * 3(n)d | ||||
| d | população | EQM | VAR | EQM | VAR |
| 1 | N(10, 1) | 2,780 | 0,003 | 1,418 | 0,004 |
| 2 | N(10, 10) | 27,812 | 0,034 | 14,216 | 0,043 |
| 3 | N(10, 100) | 278,101 | 0,315 | 141,884 | 0,409 |
Provas
| T * 1(n)d | T * 3(n)d | ||||
| d | população | EQM | VAR | EQM | VAR |
| 1 | N(10, 1) | 2,780 | 0,003 | 1,418 | 0,004 |
| 2 | N(10, 10) | 27,812 | 0,034 | 14,216 | 0,043 |
| 3 | N(10, 100) | 278,101 | 0,315 | 141,884 | 0,409 |
Provas
| T * 1(n)d | T * 3(n)d | ||||
| d | população | EQM | VAR | EQM | VAR |
| 1 | N(10, 1) | 2,780 | 0,003 | 1,418 | 0,004 |
| 2 | N(10, 10) | 27,812 | 0,034 | 14,216 | 0,043 |
| 3 | N(10, 100) | 278,101 | 0,315 | 141,884 | 0,409 |
Provas
| T * 1(n)d | T * 3(n)d | ||||
| d | população | EQM | VAR | EQM | VAR |
| 1 | N(10, 1) | 2,780 | 0,003 | 1,418 | 0,004 |
| 2 | N(10, 10) | 27,812 | 0,034 | 14,216 | 0,043 |
| 3 | N(10, 100) | 278,101 | 0,315 | 141,884 | 0,409 |
Provas
| T * 1(n)d | T * 3(n)d | ||||
| d | população | EQM | VAR | EQM | VAR |
| 1 | N(10, 1) | 2,780 | 0,003 | 1,418 | 0,004 |
| 2 | N(10, 10) | 27,812 | 0,034 | 14,216 | 0,043 |
| 3 | N(10, 100) | 278,101 | 0,315 | 141,884 | 0,409 |
Provas
| T * 1(n)d | T * 3(n)d | ||||
| d | população | EQM | VAR | EQM | VAR |
| 1 | N(10, 1) | 2,780 | 0,003 | 1,418 | 0,004 |
| 2 | N(10, 10) | 27,812 | 0,034 | 14,216 | 0,043 |
| 3 | N(10, 100) | 278,101 | 0,315 | 141,884 | 0,409 |
Provas
| análise de variância | |||||
| fonte de variação |
graus de liberdade |
soma dos quadrados |
quadrado médio |
razão F | p-valor |
| modelo de regressão | 3 | 210,8 | 70,3 | 140,6 | < 0,0001 |
| J | 1 | 108,5 | |||
| !$ \ell !$n(POPiJ) | 1 | 93,5 | |||
| J × !$ \ell !$n(POPiJ) | 1 | 142,8 | |||
| J,!$ \ell !$n(POPiJ) | 2 | 201,4 | |||
| J,J × !$ \ell !$n(POPiJ) | 2 | 191,3 | |||
| !$ \ell !$n(POPiJ),J × !$ \ell !$n(POPiJ) | 2 | 206,8 | |||
| erro | 126 | 64,7 | 0,5 | ||
Provas
| análise de variância | |||||
| fonte de variação |
graus de liberdade |
soma dos quadrados |
quadrado médio |
razão F | p-valor |
| modelo de regressão | 3 | 210,8 | 70,3 | 140,6 | < 0,0001 |
| J | 1 | 108,5 | |||
| !$ \ell !$n(POPiJ) | 1 | 93,5 | |||
| J × !$ \ell !$n(POPiJ) | 1 | 142,8 | |||
| J,!$ \ell !$n(POPiJ) | 2 | 201,4 | |||
| J,J × !$ \ell !$n(POPiJ) | 2 | 191,3 | |||
| !$ \ell !$n(POPiJ),J × !$ \ell !$n(POPiJ) | 2 | 206,8 | |||
| erro | 126 | 64,7 | 0,5 | ||
Provas
| análise de variância | |||||
| fonte de variação |
graus de liberdade |
soma dos quadrados |
quadrado médio |
razão F | p-valor |
| modelo de regressão | 3 | 210,8 | 70,3 | 140,6 | < 0,0001 |
| J | 1 | 108,5 | |||
| !$ \ell !$n(POPiJ) | 1 | 93,5 | |||
| J × !$ \ell !$n(POPiJ) | 1 | 142,8 | |||
| J,!$ \ell !$n(POPiJ) | 2 | 201,4 | |||
| J,J × !$ \ell !$n(POPiJ) | 2 | 191,3 | |||
| !$ \ell !$n(POPiJ),J × !$ \ell !$n(POPiJ) | 2 | 206,8 | |||
| erro | 126 | 64,7 | 0,5 | ||
Provas
Caderno Container