Foram encontradas 656 questões.
Em 2020, o fechamento das escolas para conter a propagação do vírus da Covid-19 e a migração obrigatória para o ensino emergencial remoto demonstraram fragilidades do ensino no Brasil. Após a pandemia, já no final de 2022, a Conferência Nacional de Educação (Conae) debateu, entre outros tópicos, as tecnologias da informação e da comunicação nas escolas. O tema deverá ser incluído no Plano Nacional de Educação 2024-2034, guia para as políticas públicas do próximo decênio.
A relevância das TIC nas discussões sobre educação evidencia a importância de qual tipo de linguagem?
Provas
Na redação oficial de uma comunicação, em relação ao emprego dos pronomes de tratamento e à concordância com eles, está de acordo com a norma-padrão da língua portuguesa o seguinte período:
Provas
- Manual de Redação da Presidência da RepúblicaAs Comunicações OficiaisSignatáriosFechos e Identificação do Signatário
Na identificação do signatário de comunicação oficial da administração pública federal, um exemplo de redação correta do nome de um cargo ocupado por pessoa do sexo feminino, respeitando-se a norma-padrão da língua portuguesa, é o seguinte:
Provas
Em meados dos anos 1940, Adorno e Horkheimer criam o conceito de indústria cultural, e analisam
Provas
O clickbait é uma linguagem para
Provas
A economia política da comunicação é uma teoria que começa a se desenvolver nos anos 1960. Um de seus principais expoentes na América Latina é César Bolaño, que escreveu em 2007 um artigo de onde foi retirado o texto abaixo.
A problemática da subsunção do trabalho é, portanto, crucial, e a expropriação recorrente do conhecimento produzido pela classe trabalhadora faz parte, de uma ou de outra forma, dessa problemática, desde o início. A sua acumulação primitiva, primeiro, é que permite, de fato, o real domínio do capital sobre processos de trabalho que ele próprio não inventou, mas herdou do artesanato, aperfeiçoando-os, ao adicionar-lhes o trabalho de mecânicos, engenheiros e outros intelectuais. Essa reorganização dos processos de trabalho tinha como objetivo ampliar a produtividade e redundou, com a Primeira Revolução Industrial, na desqualificação generalizada da classe trabalhadora e a decorrente concentração do conhecimento no interior do capital. A isto Marx chama subsunção real do trabalho no capital, e a Segunda Revolução Industrial é definida por ele como a extensão desse processo ao setor produtor das próprias máquinas, com o que as potências do trabalho, a serviço da acumulação capitalista, ampliam- -se de forma exponencial. [...] O significado último do desenvolvimento das tecnologias da informação e da comunicação (TIC), vinculadas à Terceira Revolução Industrial, reside justamente na subsunção desse trabalho intelectual, o que vem acompanhado de uma intelectualização geral de todos os processos de trabalho convencionais e do consumo, de modo que o conjunto das relações de produção e das relações sociais em geral se altera para adequar-se às novas exigências da acumulação capitalista.
BOLAÑO, C. Trabalho, comunicação e desenvolvimento. Liinc em Revista, Rio de Janeiro, v.3, n.1, mar. 2007, p.33-42. Disponível em: http://www.ibict.br/liinc. Acesso em: 20 dez. 2023. Adaptado.
O ponto central discutido no texto é a(o)
Provas
No aprendizado não supervisionado, os dados de treinamento não têm rótulos. O objetivo é agrupar instâncias semelhantes em clusters. Nesse contexto, suponha que se deseja executar um algoritmo de agrupamento para tentar detectar grupos de visitantes semelhantes em um blog. Em nenhum momento é informado ao algoritmo a que grupo um visitante pertence, mas ele encontra essas conexões sem ajuda. Por exemplo, o algoritmo pode notar que 40% dos visitantes são homens que adoram histórias em quadrinhos e, geralmente, leem o blog à noite, enquanto 20% são jovens amantes de ficção científica que visitam o blog durante os fins de semana, e assim por diante. Deseja-se, nesse caso, usar um algoritmo de agrupamento hierárquico para subdividir cada grupo em grupos menores, o que pode ajudar a direcionar as postagens do blog para cada grupo específico.
Nesse cenário, qual é o algoritmo mais apropriado para fazer o agrupamento desejado?
Provas
A biblioteca Scikit-Learn emprega o algoritmo Classification And Regression Tree (CART) para treinar Árvores de Decisão. O algoritmo CART baseia-se na recursividade e na estratégia de divisão binária para construir uma árvore de decisão. Inicialmente, a árvore é representada por um único nó, que contém todos os dados de treinamento. A cada passo, o algoritmo busca a melhor maneira de dividir o conjunto de dados. A recursividade continua até que uma condição de parada seja atendida, como atingir uma profundidade máxima da árvore. Uma vez construída a árvore, a fase de predição ocorre ao percorrer a estrutura da árvore de acordo com as condições estabelecidas nos nós, levando a uma predição (inferência) para uma determinada entrada.
Considerando-se que n corresponde ao número de features e m ao número de instâncias, qual é a complexidade computacional assintótica de predição para árvores de decisão treinadas com o algoritmo CART?
Provas
- Inteligência ArtificialMachine LearningAlgoritmosÁrvores de Decisão
- ProgramaçãoPythonScikit-learn (Sklearn)
As árvores de decisão são um modelo de aprendizado de máquina que opera por meio da construção de uma estrutura em forma de árvore para tomar decisões e que oferece uma compreensão clara da lógica de decisão e da hierarquia de características que contribuem para as predições finais. Elas são versáteis e podem ser usadas tanto para tarefas de classificação quanto para as de regressão.
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do Scikit-Learn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
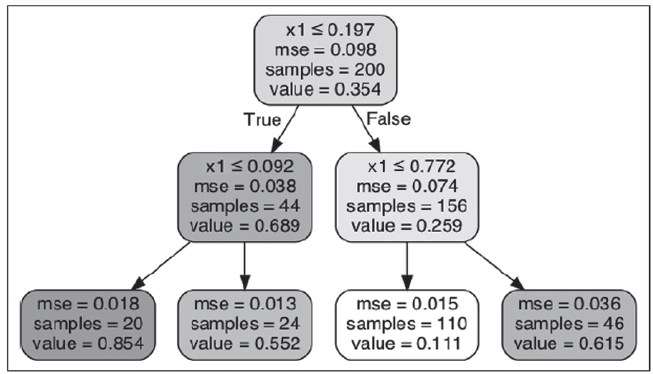
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques
to Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
Provas
Em uma nota técnica publicada em 2022 pelo Ipea, sobre população em situação de rua, foi utilizada a técnica de análise de componente principal (PCA).
Na análise por PCA, a primeira componente principal de um conjunto de dados representa a
Provas
Caderno Container