Foram encontradas 24.509 questões.
A tabela PUBSTREAM registra os usuários de uma plataforma de streaming de filmes escolhendo seus filmes favoritos.
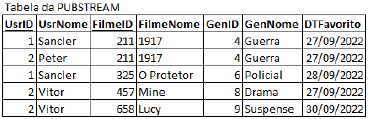
As colunas UsrID e FilmeID compõe a chave primária da tabela.
- Cada usuário possui um identificador único UsrID e um nome UsrNome.
- Cada filme possui um identificador único FilmeID e um nome FilmeNome.
- Cada gênero possui um identificador único GenID e um nome GenNome.
- O dia em que o usuário "favorita" o filme é registrado na coluna DTFavorito.
A tabela apresentada está desnormalizada. Considerando as dependências funcionais, assinale a opção que descreve a passagem corretamente à terceira forma normal (3FN).
Provas
O sistema de gerenciamento de banco de dados oferece ao administrador diferentes indicadores para obter informações sobre o ambiente. No caso do SGBD SQL Server, quando se trata de analisar a performance de consultas, um dos indicadores observados é o chamado tipo de espera (Wait Type).
Considere que o sistema de controle de pagamentos da metalúrgica Ferro Forte está no SGBD SQL Server, e vem apresentando perda de performance no processo de fechamento da folha de pagamento. O analista de banco de dados constata que o tipo de espera mais comum se refere ao paralelismo do plano de execução (CXPACKECT).
Visando a otimizar a performance da consulta em relação aos recursos de CPU e de memória do servidor, assinale a opção que lista os parâmetros que devem ser ajustados para melhorar o paralelismo.
Provas
O particionamento em um SGBD geralmente é empregado em tabelas com grande volume de dados. Como resultado desse processo são gerados conjuntos menores de dados. Essa configuração pode contribuir para melhor desempenho de consultas.
Considere que, no banco de dados do sistema financeiro da empresa XPTO, exista uma tabela chamada Fatura. Essa tabela possui bilhões de tuplas e não está particionada. O Analista de banco de dados propõe particionar a tabela Fatura utilizando a coluna Ano.
O SGBD utilizado para gerenciar o banco de dados do sistema é o SQL Server. Com relação aos itens que devem ser cumpridos para realizar o particionamento da tabela, analise as afirmativas a seguir:
I. Os componentes fundamentais para particionar a tabela são: elaborar uma função de partição, criar um esquema de partição, especificar novo grupo de arquivos no banco de dados, criar arquivos de dados para cada ano e criar índice clusterizado contendo a coluna utilizada para o particionamento.
II. A função de partição com RANGE RIGHT sobre uma coluna datetime ou datetime2 indica que as tuplas registradas meia noite ficaram em outra partição, ou seja, sendo o primeiro elemento da fragmentação seguinte.
III. A função de partição não permite parâmetro de input dos tipos de dados varchar ou nvarchar.
IV. Se não for especificado o método adotado para criar os intervalos de fragmentação na função de partição por padrão é adotado o RANGE LEFT.
Está correto o que se afirma em
Provas
Disciplina: TI - Banco de Dados
Banca: Legalle
Orgão: Câm. Porto Alegre-RS
CREATE trata-se de um comando do tipo do SQL trata-se de outro comando do mesmo tipo. Qual alternativa preenche, CORRETA e respectivamente. as lacunas acima?
Provas
Considere o seguinte trecho de instruções SQL.
CREATE TABLE tabela (ID INT);
ALTER TABLE tabela ADD COLUMN coluna;
SELECT * FROM tabela WHERE ID > 15 OR ID < 20;
Em relação a essas instruções, é correto afirmar:
Provas
Sobre a normalização em banco de dados, analise as afirmativas seguintes e atribua-lhes V (verdadeiro) ou F (falso).
( ) Uma relação está na primeira forma normal (1FN) se todos os atributos são atômicos e não forem multivalorados.
( ) Uma relação está na segunda forma normal (2FN) se ela estiver na 1FN e os atributos chaves forem independentes da chave primária.
( ) Uma relação está na terceira forma normal (3FN) quando, na análise de uma tupla, não se encontra um atributo não chave dependente de outro atributo não chave.
A sequência correta, de cima para baixo, é
Provas
Considere que os comandos SQL descritos a seguir são executados em sequência.
CREATE SCHEMA IF NOT EXISTS concurso;
USE concurso;
CREATE TABLE TABELA1 (
id INT NOT NULL AUTO_INCREMENT,
nome VARCHAR (50) NOT NULL,
idade INT NOT NULL,
PRIMARY KEY (ID)
);
CREATE TABLE TABELA2 (
id INT NOT NULL AUTO_INCREMENT,
id_tabela1 INT REFERENCES TABELA1(id),
area VARCHAR (50) NOT NULL,
PRIMARY KEY (ID)
);
INSERT INTO TABELA1 (id, nome, idade) VALUES (1, "Fulana", 20), (2, "Ciclano", 45), (3, "Beltrano", 32), (4, "Fulano", 27);
INSERT INTO TABELA2 (area,id_tabela1) VALUES ("A", 1), ("B", 1), ("C", 4), ("B", 2), ("C", 3), ("D", 4), ("E", 3), ("E", 3), ("C", 4), ("F", 2), ("B", 3);
SELECT COUNT(t1.id) FROM TABELA1 t1, TABELA2 t2 WHERE t2.id_tabela1 = t1.id and t1.idade > 25 and t2.area != "B";
O valor retornado após a execução do comando SELECT é
Provas
Para responder às questões 44 e 45, considere a situação descrita a seguir. Um técnico precisa importar o arquivo CSV (Comma-Separated Values) do Quadro 1 abaixo, em um banco de dados relacional. A primeira linha do arquivo contém o cabeçalho que define os atributos C1, C2, C3 e C4, enquanto as demais linhas são os valores assumidos por esses atributos em diferentes situações. O técnico deve executar a análise observando apenas o conteúdo disponível, sem levar em consideração quaisquer informações sobre a semântica dos atributos.
C1,C2,C3,C4 1,a,x,02 2,d,y,14 1,a,x,05 2,d,y,01 1,e,x,13 2,d,y,16 1,a,x,08 |
Quadro 1 – Conteúdo de um arquivo CSV
O técnico inicia fazendo uma análise preliminar das dependências funcionais entre esses atributos. Utilizando a notação !$ X !$ → !$ Y !$ para dizer que X determina funcionalmente Y, assinale a alternativa correta em relação às dependências funcionais observadas no arquivo CSV em questão.
Provas
Tabela visits

Tabela purchases

A tabela visits apresenta todos os usuários em quem se tem interesse e que visitaram determinado site. A tabela purchases, por outro lado, mostra todas as compras realizadas por todos os visitantes. As colunas que têm o sufixo _ts indicam data e hora em que o evento ocorreu.
Considerando essas informações, assinale a alternativa correspondente à query que deve ser utilizada para retornar uma cópia exata da coluna user da tabela visits, acrescida de uma coluna que indique quantas compras cada usuário realizou.
Provas
Em bancos de dados SQL, um recurso é utilizado como um tipo especial de procedimento armazenado, que é executado sempre que há uma tentativa de modificar os dados de uma tabela que é protegida por ele, antes ou depois das operações de INSERT, UPDATE e DELETE de registros. Esse recurso é denominado:
Provas
Caderno Container