Foram encontradas 5.009 questões.
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: SEFAZ-SE
Na mineração de texto, o processo utilizado para remover os prefixos e sufixos de palavras, de modo a permanecer somente a raiz delas, com a finalidade de melhorar o armazenamento, é conhecido como
Provas
Em uma situação hipotética, o fato de pessoas atuarem de forma diferenciada para resolver um mesmo problema é explicado pelo conceito de
Provas
Julgue o item seguinte, a respeito de data warehouse e OLAP.
Em um data warehouse, as tabelas contendo dados multidimensionais são denominadas tabelas de fatos; normalmente, elas são muitos grandes.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Julgue o próximo item, relativo a redes neurais artificiais (RNA).
Em RNA, o uso de early stopping, ainda que não evite o overfitting, permite calcular com mais precisão a classificação nos dados de validação e, assim, melhorar a acurácia do treinamento.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os hiperparâmetros de um modelo são todos os parâmetros que podem ser definidos antes do inicio do treinamento, diferentemente dos parâmetros do modelo, que são aprendidos durante o treino do modelo. A busca por hiperparâmetros de determinado algoritmo de aprendizado de máquina que retorne o melhor desempenho medido em um conjunto de validação deu origem ao conceito de otimização de hiperparâmetros.
Acerca dos conceitos de otimização de hiperparâmetros de modelos de aprendizado de máquinas, julgue o item que se segue.
A otimização bayesiana se utiliza do conceito de probabilidade para encontrar o valor de entrada de uma função que possa retornar o menor valor de saída possível. Nesse método, o número de iterações de pesquisa pode ser reduzido a partir da escolha dos valores de entrada, levando em consideração os resultados anteriores, o que caracteriza um processo iterativo.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os algoritmos de aprendizado supervisionado partem de um conjunto de dados rotulados para fazer previsões sobre novos dados não rotulados. O Python scikit-learn é uma biblioteca de código aberto utilizada para codificações de rotinas em aprendizado de máquina supervisionado; ela oferece ainda uma série de ferramentas utilizadas no ajuste de modelos e no pré-processamento de dados, para a seleção e avaliação de modelos.
Tendo como referência essas informações, julgue o item a seguir.
No código a seguir, DecisionTreeClassifier é um classificador que recebe como entrada dois arrays: um array X, de valores inteiros, contendo os rótulos de classe para as amostras de treinamento; e um array Y, esparso ou denso, contendo as amostras de treinamento.
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, Y)
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
Os modelos ditos fracos, também chamados modelos de base, muitas vezes são combinados com o objetivo de se construir um modelo mais forte, no qual a variância e o viés atinjam equilíbrio satisfatório. Esse procedimento, denominado ensembles, é muito utilizado em ciência de dados e aprendizado de máquinas. Quanto às formas de ensembles, julgue o próximo item.
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
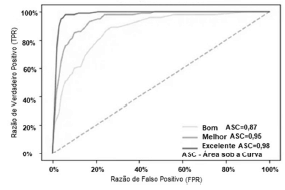
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
As curvas ROC a seguir mostram a taxa de especificidade (verdadeiros positivos) versus a taxa de sensibilidade (falsos positivos) do modelo adotado; a linha tracejada é a linha de base da métrica de avaliação e define uma adivinhação aleatória.
Provas
Disciplina: TI - Ciência de Dados e BI
Banca: CESPE / CEBRASPE
Orgão: Petrobrás
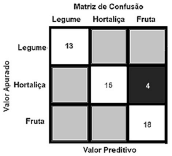
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
Provas
A mineração de dados (Data Mining) envolve um conjunto de algoritmos e ferramentas que são utilizados para a exploração de dados.
Assinale o algoritmo/método usado na extração de regras de associação.
Provas
Caderno Container