Foram encontradas 55.987 questões.
A biblioteca numpy é uma das mais usadas no Python para ciência de dados. É correto afirmar que o seguinte código em Python calcula.
import numpy as np
#Dados de vendas por dia da semana (segunda a domingo)
v = np.array([[120,150,100,80,200,180,160]
[130,170,110,90,190,170,150]])
def func1(v):
r = np.std(v, axis =0)
return r
s = func1(v)
d= np.argmax(s)
print("Resultado 1:",s)
print("Resultado 2:",d)
Provas
O tratamento de dados na linguagem R pode ser apresentado de múltiplas formas. O seguinte código em R tem como objetivo criar um
library(ggplot2)
dados < - data.frame(
Aluno = c {"João" , "João", "João", "João", "João"),
Nota = c (7,8, 6, 9,5)
)
ggplot (data = dados, aes( x = Aluno, y = Nota))+
geom_bar (star = "identity", fill = "skyblue")+
labs(title = "Distribuição de Notas",
x = "Aluno",
y= "Nota") +
theme_minimal ( )
Provas
O uso da biblioteca NLTK ajuda no processamento de linguagem natural. É correto afirmar que o seguinte código Python tem como objetivo
from nltk.stem import PorterStemmer
stemmer = PorterStemmer ( )
palavras =["running", "ran", "runs", "runner", "easily", "fairly",
"fairness"]
for palavra in palavras:
stem = stemmer.stem(palavra)
print(f"{palavra}: {stem}")
Provas
No seguinte código em Python temos um DataFrame básico basic_df com IDs e nomes, e um DataFrame adicional additional_df com IDs, idades e cidades. Usamos o método merge() do pandas para combinar os dois DataFrames com base no ID, adicionando as colunas de idade e cidade ao DataFrame básico para enriquecimento. O resultado é um novo DataFrame enriched_df com dados adicionais integrados.
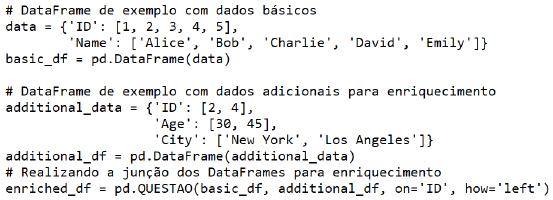
É correto afirmar que para que o código funcione conforme relatado neste enunciado, a função QUESTAO() deve ser substituída por:
Provas
Avalie o seguinte código em Python e assinale a resposta referente ao processo de data cleansing executado:
import pandas as pd
df = pd. read_csv('data.csv')
df["Calories"].fillna(130, inplace = True)
Provas
O seguinte código em Python conta com dados duplicado (ID no valor de 3 e Name no valor de Charlie).
import pandas as pd
data = {'ID': [1,2,3,3,4,5],
'Name': ['Alice', 'Bob', 'Charlie' Charlie', 'David', "Emily'}
df = pd.DataFrame(data)
deduplicated_df = df. drop_duplicates( )
O código que implementa deduplicação é:
Provas
Encontrar informações indesejadas é necessário no tratamento de dados, principalmente em strings. Analise o seguinte código e assinale a alternativa que contém a saída da última linha.
import re
text = "Hello, world! This is an example string with some numbers:
1234567890"
clean_text = re.sub(r'\d+', ", text)
print(clean_text)
Provas
Valores ausentes geralmente requerem tratamento de dados em ciência de dados. Analise o seguinte código em Python e assinale a alternativa que apresenta o que é executado pela última linha:
from numpy import nan
from pandas import read_csv
dataset = read_csv('pima_indians-diabetes.csv'.header=Nome)
dataset[[1,2,3,4,5]] = dataset[[1,2,3,4,5]]. replace (0, nan)
dataset.dropna(inplace= True)
Provas
O desempenho de muitos algoritmos de aprendizado de máquina degrada para variáveis que têm distribuições de probabilidade não padrão. Uma abordagem é usar a transformação da variável numérica para ter uma distribuição de probabilidade discreta, onde cada valor numérico é atribuído a um rótulo e os rótulos têm uma relação ordenada (ordinal). Assinale a alternativa que apresenta a função da biblioteca sklearn para discretização de dados.
Provas
Analise o seguinte código Python que implementa normalização numérica e assinale a alternativa que apresenta a saída da linha 5:
1 from sklearn import preprocessing
2 import numpy as np
3 x = np.array ([2,3,5,6,7,4,8,7,6])
4 n =preprocessing.normalize([x_array])
5 print(n)
Provas
Caderno Container