Uma tarefa muito comum durante a etapa de pré-processamento de dados é o tratamento de valores ausentes. A linguagem Python possui uma biblioteca muito utilizada pelos cientistas de dados, denominada Pandas, que permite realizar o processo de transformação dos dados de maneira bem prática. Considere os dados exibidos pela figura abaixo:
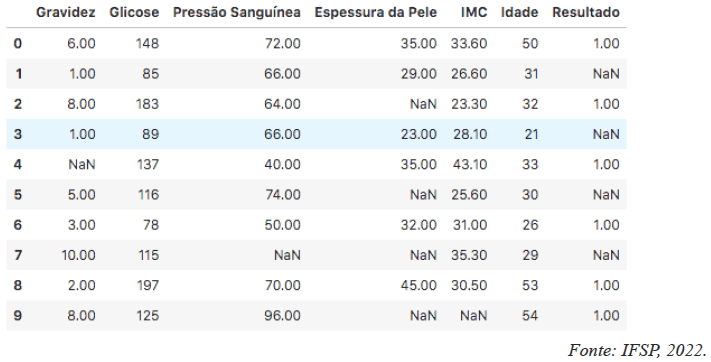
Pela figura, é possível observar que existem diversos valores ausentes, identificados por NaN. Ao analisar essas informações, o cientista de dados decide substituir os valores ausentes em cada coluna, da seguinte forma:
• Gravidez: substituir NaN pelo valor 0;
• Pressão Sanguínea: substituir NaN pela média dos valores da coluna;
• Espessura da Pele: substituir NaN pela moda dos valores da coluna;
• IMC: substituir NaN pela mediana dos valores da coluna;
• Resultado: substituir NaN pelo valor 0.
O cientista de dados armazenou os valores dentro de um dataframe do Pandas, chamado df. Para realizar a substituição dos valores ausentes, ele decide executar o seguinte comando:
df.fillna(value=valores, inplace=True)
Observe que o argumento “value” recebe um dicionário do Python. Esse dicionário contém as instruções para atualizar os valores das colunas, tal como o cientista de dados deseja. Assinale a alternativa correta, que indica o trecho de código relacionado a esse dicionário de dados.