Foram encontradas 50 questões.
A biblioteca NLTK (Natural Language Toolkit) engloba ferramentas para processamento de linguagem natural, tais como funções de tokenização e radicalização. Dessa forma, considerando o código apresentado:
frase = “Não esqueçam a lista de materiais: 1 lápis e 2 canetas!”
from nltk.tokenize import RegexpTokenizer
tokenizador = RegexpTokenizer(r’w+’)
tokens = tokenizador.tokenize(frase)
print(tokens)
Qual o resultado correto?
Provas
Uma rede neural é um modelo preditivo motivado pela forma como o cérebro funciona. Redes neurais artificiais são formadas por neurônios artificiais, que desenvolvem cálculos similares sobre suas entradas. Elas podem resolver uma variedade de problemas, tais como o reconhecimento de caligrafia e a detecção facial, entre outros. São geralmente representadas por meio de um grafo orientado, onde os vértices representam os neurônios e as arestas representam as sinapses. Podem ser classificadas em três categorias específicas: Redes Neurais Feed-Forward, Redes Recorrentes e Redes Conectadas Simetricamente. Dentro dessas categorias, existem diversos tipos de arquiteturas.
Assinale a alternativa que define corretamente uma Rede Neural Perceptron Multicamadas.
Provas
O Processamento de Linguagem Natural (PLN) é a subárea da Inteligência Artificial responsável por estudar a capacidade e as limitações de uma máquina de entender a linguagem dos seres humanos. Para poder realizar essa modelagem, são necessários pré-processamentos que abstraem e estruturam a língua, deixando apenas aquilo que representa uma informação relevante. Uma das etapas desse processo compreende a normalização. Uma tarefa que pode ser realizada dentro do processo de normalização é denominada de tokenização lexical. Considere a seguinte sentença:
A área de Ciência de Dados é muito interessante!
Assinale a alternativa correta que representa o resultado da tokenização lexical para essa sentença.
Provas
Entre os modelos de aprendizado de máquina mais comuns, estão as árvores de decisão. Elas são métodos de aprendizado de máquinas muito utilizados em tarefas de classificação e regressão. Em problemas de classificação, os modelos em árvore são designados de árvore de decisão. Para resolver um problema de decisão, esse tipo de método utiliza a estratégia de dividir para conquistar. Uma proposta natural é rotular cada conjunto da divisão por sua classe mais frequente e escolher a divisão que tem menores erros. O conceito fundamental nessa proposta é denominado de entropia. Considerando as árvores de decisão, assinale a alternativa que define corretamente o conceito de entropia.
Provas
Machine Learning, ou aprendizado de máquina, é um subcampo da inteligência artificial baseada na ideia de que os sistemas podem aprender a identificar padrões e tomar decisões, por meio da análise de dados. De acordo com o tipo de técnica utilizada no processo de aprendizagem, existem vários algoritmos que podem ser aplicados para gerar o modelo de aprendizado. Os parâmetros desse modelo podem ser atualizados por meio de técnicas de otimização. Com base nessas informações, assinale a alternativa correta.
Provas
Você recebeu um chamado para colaborar no desenvolvimento de um dos módulos do software acadêmico. O referido módulo deve apresentar um gráfico estatístico para simplificar a interpretação dos dados e facilitar a tomada de decisões. Anexo ao chamado, consta um exemplo de uma matriz de dados extraída do Sistema Gerenciador de Banco de Dados oficial da instituição, possuindo dados relacionados à altura, peso, idade, renda familiar e número de reprovações. Assinale a alternativa que representa o tipo de gráfico mais adequado para análise dos referidos dados.
Provas
Trabalhar com álgebra linear está associado aos vetores e matrizes, com suas regras e cálculos. Para isso, é necessário conhecer tanto a matemática envolvida quanto os recursos da linguagem de programação. Assinale a alternativa correta que implementa o cálculo algébrico apresentado:
!$ A = \begin{bmatrix} 10 & 20 & 30 \\ 40 & 50 & 60 \\ 70 & 80 & 90 \end{bmatrix} \ B = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix} \ C = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix} !$
Sendo D = (A+B)•C
Provas
a = {1,2,3}
b = (1,2,3)
c = [1,2,3]
d = {“a”: 1,”b”: 2,”c”: 3}
print(type(a))
print(type(b))
print(type(c))
print(type(d))
Assinale a alternativa que corresponde à saída gerada pelo algoritmo acima:
Provas
from scipy import stats
…
Y, Z = stats.normaltest(X)
Considerando o trecho do algoritmo acima, assinale a alternativa que corresponde ao significado do valor de Z.
Provas
Uma tarefa muito comum durante a etapa de pré-processamento de dados é o tratamento de valores ausentes. Na linguagem R, os valores ausentes são representados por NA (Not Avaliable). Considere os dados exibidos pela figura abaixo:
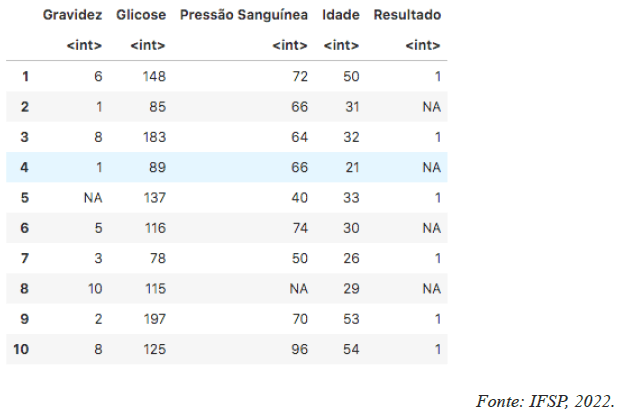
Esses dados correspondem aos valores que foram carregados e armazenados em um dataframe da linguagem R. A linguagem R, assim como a linguagem Python, é muito utilizada na área de Ciência de Dados. Ela oferece diversas bibliotecas que podem ser empregadas para auxiliar nas etapas de pré-processamento e transformação dos dados. Ao analisar as informações exibidas pela figura, o cientista de dados percebe a existência de diversos valores ausentes e decide substituí-los da seguinte forma:
• Gravidez: substituir NA pelo valor 0;
• Pressão Sanguínea: substituir NA pela média dos valores da coluna;
• Resultado: substituir NA pelo valor 0.
Assinale a alternativa correta, que indica o trecho de código escrito em linguagem R, que pode ser utilizado para realizar essa tarefa.
Provas
Caderno Container