Foram encontradas 120 questões.
A seguir, são apresentados um modelo de banco de dados, consistindo de quatro tabelas, bem como os comandos SQL utilizados para a criação e a inserção de dados nessas tabelas.
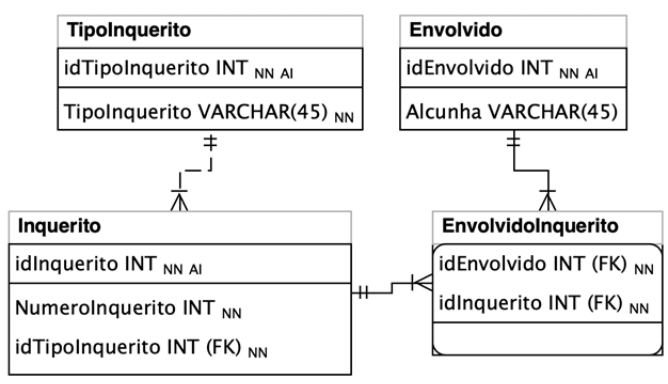
criação das tabelas
CREATE TABLE Envolvido ( idEnvolvido INT NOT NULL, Alcunha VARCHAR(45) NULL DEFAULT NULL, PRIMARY KEY (idEnvolvido)); CREATE TABLE TipoInquerito ( idTipoInquerito INT NOT NULL, TipoInquerito VARCHAR(45) NOT NULL, PRIMARY KEY (idTipoInquerito)); CREATE TABLE Inquerito ( idInquerito INT NOT NULL, NumeroInquerito INT NOT NULL, idTipoInquerito INT NOT NULL, PRIMARY KEY (idInquerito), FOREIGN KEY (idTipoInquerito) REFERENCES TipoInquerito (idTipoInquerito)); CREATE TABLE EnvolvidoInquerito ( idEnvolvido INT NOT NULL, idInquerito INT NOT NULL, PRIMARY KEY (idEnvolvido, idInquerito), FOREIGN KEY (idEnvolvido) REFERENCES Envolvido (idEnvolvido), FOREIGN KEY (idInquerito) REFERENCES Inquerito (idInquerito));
inserção de dados nas tabelas
INSERT INTO Envolvido (idEnvolvido, Alcunha) VALUES (10, 'Gargamel'); INSERT INTO Envolvido (idEnvolvido, Alcunha) VALUES (20, 'Vingador'); INSERT INTO Envolvido (idEnvolvido, Alcunha) VALUES (30, 'Esqueleto'); INSERT INTO TipoInquerito (idTipoInquerito, TipoInquerito) VALUES (11, 'Inquérito Policial'); INSERT INTO TipoInquerito (idTipoInquerito, TipoInquerito) VALUES (12, 'Inquérito Civil'); INSERT INTO TipoInquerito (idTipoInquerito, TipoInquerito) VALUES (13, 'Notícia-Crime'); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES (1,111, 13); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES(2,121, 12); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES(3,131, 13); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES (4,444, 11); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES(5,555, 13); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (10, 1); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (20, 1); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (20, 4); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (30, 1); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (30, 3); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (30, 5);
Considerando as informações precedentes, julgue o próximo item, relativos à SQL.
Considere o comando SQL que se segue.
SELECT DISTINCT COUNT(E.Alcunha) as
Quantidade
FROM Envolvido AS E
INNER JOIN EnvolvidoInquerito AS EI ON
E.idEnvolvido = EI.idEnvolvido
WHERE ALCUNHA LIKE '%E%';
Ao ser executado, esse comando apresentará o resultado a seguir.
Quantidade 1
Provas
A seguir, são apresentados um modelo de banco de dados, consistindo de quatro tabelas, bem como os comandos SQL utilizados para a criação e a inserção de dados nessas tabelas.
criação das tabelas
CREATE TABLE Envolvido ( idEnvolvido INT NOT NULL, Alcunha VARCHAR(45) NULL DEFAULT NULL, PRIMARY KEY (idEnvolvido)); CREATE TABLE TipoInquerito ( idTipoInquerito INT NOT NULL, TipoInquerito VARCHAR(45) NOT NULL, PRIMARY KEY (idTipoInquerito)); CREATE TABLE Inquerito ( idInquerito INT NOT NULL, NumeroInquerito INT NOT NULL, idTipoInquerito INT NOT NULL, PRIMARY KEY (idInquerito), FOREIGN KEY (idTipoInquerito) REFERENCES TipoInquerito (idTipoInquerito)); CREATE TABLE EnvolvidoInquerito ( idEnvolvido INT NOT NULL, idInquerito INT NOT NULL, PRIMARY KEY (idEnvolvido, idInquerito), FOREIGN KEY (idEnvolvido) REFERENCES Envolvido (idEnvolvido), FOREIGN KEY (idInquerito) REFERENCES Inquerito (idInquerito));
inserção de dados nas tabelas
INSERT INTO Envolvido (idEnvolvido, Alcunha) VALUES (10, 'Gargamel'); INSERT INTO Envolvido (idEnvolvido, Alcunha) VALUES (20, 'Vingador'); INSERT INTO Envolvido (idEnvolvido, Alcunha) VALUES (30, 'Esqueleto'); INSERT INTO TipoInquerito (idTipoInquerito, TipoInquerito) VALUES (11, 'Inquérito Policial'); INSERT INTO TipoInquerito (idTipoInquerito, TipoInquerito) VALUES (12, 'Inquérito Civil'); INSERT INTO TipoInquerito (idTipoInquerito, TipoInquerito) VALUES (13, 'Notícia-Crime'); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES (1,111, 13); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES(2,121, 12); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES(3,131, 13); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES (4,444, 11); INSERT INTO Inquerito (idInquerito, NumeroInquerito, idTipoInquerito) VALUES(5,555, 13); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (10, 1); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (20, 1); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (20, 4); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (30, 1); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (30, 3); INSERT INTO EnvolvidoInquerito (idEnvolvido, idInquerito) VALUES (30, 5);
Considerando as informações precedentes, julgue o próximo item, relativos à SQL.
Considere o comando SQL que se segue.
SELECT DISTINCT E.Alcunha,
COUNT(I.idInquerito)
AS Quantidade
FROM Envolvido AS E
INNER JOIN EnvolvidoInquerito AS EI ON
E.idEnvolvido = EI.idEnvolvido
INNER JOIN Inquerito AS I ON EI.idInquerito =
I.idInquerito
GROUP BY E.Alcunha;
Esse comando, ao ser executado, apresentará o resultado a seguir.
Alcunha Quantidade Gargamel 1 Vingador 1 Esqueleto 1
Provas
Para certo conjunto de dados que mensuram uma variável quantitativa discreta com N medições, foram determinados a média m, o desvio padrão e, para uma dada proporção p, o p-quantil q(p).
Com base nessa situação hipotética, julgue os itens seguintes, considerando que há acesso aos dados originais e a nenhuma outra informação acerca do conjunto.
A média e o desvio padrão fornecem informações suficientes para uma adequada percepção da eventual assimetria da distribuição dos dados.
Provas
|
unidade da Federação |
tráfico de entorpecentes |
lavagem de dinheiro |
corrupção |
total |
| estado A | 32 | 20 | 15 | 67 |
| estado B | 25 | 18 | 20 | 63 |
| estado C | 28 | 15 | 12 | 55 |
| estado D | 40 | 10 | 5 | 55 |
| estado E | 10 | 25 | 30 | 65 |
Com base nos dados hipotéticos precedentes, relativos a crimes federais investigados, ao longo de 2024, em cinco unidades da Federação, julgue os itens seguintes.
A unidade da Federação com a maior frequência relativa de corrupção é o estado E.
Provas
Uma análise multivariada que está sendo realizada envolve quatro variáveis padronizadas Z1, Z2, Z3 e Z4, constituídas por duzentos registros administrativos. Para a identificação de estruturas latentes e a redução da dimensionalidade do problema, foram aplicadas a análise de componentes principais (ACP) e a análise fatorial exploratória (AFE) com extração por componentes principais. A seguir, são mostrados os autovalores para as componentes principais, que resultaram da decomposição espectral da matriz de correlações, bem como as cargas fatoriais não rotacionadas dos dois primeiros fatores extraídos.
| \( \lambda_1 \) | \( \lambda_2 \) | \( \lambda_3 \) |
| 2,3 | 0,7 | 0,5 |
| variável | fator 1 | fator 2 |
| Z1 | 0,80 | 0,10 |
| Z2 | 0,75 | 0,30 |
| Z3 | 0,60 | 0,55 |
| Z4 | 0,10 | 0,85 |
Com base nessas informações, julgue os próximos itens.
Conjuntamente, as duas primeiras componentes principais explicam 75% da variância total.
Provas
Julgue os itens a seguir, relativos à análise multivariada.
Na distribuição normal multivariada, os contornos da função densidade de probabilidade são elipsoides.
Provas
O departamento de trânsito de determinada cidade deseja estimar o número médio de infrações registradas no período de um mês na via de maior fluxo da cidade. Registros anteriores apontam um desvio padrão de 8 casos mensais.
Considerando essa situação hipotética, com confiança de 95% \( (Z_{a/2} \, = \,1,96), \) e supondo que a média amostral não difira da média populacional em mais de 2 casos, julgue o próximo item, em relação a tamanho amostral.
Caso a margem de erro fosse reduzida pela metade, mantendo-se constante os demais parâmetros, o número mínimo de infrações duplicaria.
Provas
Julgue os itens a seguir, a respeito de amostragem aleatória simples, estratificada, sistemática e por conglomerados.
O esquema de amostragem aleatória estratificada é utilizado quando a população em estudo é composta por unidades heterogêneas (subgrupos ou estratos) para a variável que se pretende estudar.
Provas
Julgue os itens a seguir, a respeito de amostragem aleatória simples, estratificada, sistemática e por conglomerados.
Erro puro é aquele que pode ocorrer quando se considera parte da população (amostra) para inferir o verdadeiro valor populacional (parâmetro).
Provas
Julgue os itens a seguir, a respeito de amostragem aleatória simples, estratificada, sistemática e por conglomerados.
Se, para estudar o perfil dos consumidores de determinada área de uma cidade, uma equipe de consultoria dividir a área de estudo em conglomerados (casas), por meio de um esquema de amostragem por conglomerados, ela deve utilizar um esquema de amostragem acidental para entrevistar os participantes da pesquisa.
Provas
Caderno Container