Foram encontradas 4.978 questões.
- ProgramaçãoPythonNumPy
- ProgramaçãoPythonPandas
- ProgramaçãoPythonScikit-learn (Sklearn)
- ProgramaçãoPythonTensorFlow/Keras
Um cientista de dados deseja analisar um conjunto de dados tabular, pré processá-lo e treinar um modelo de rede neural para prever valores contínuos. Ele utiliza Pandas para manipulação dos dados, Scikit-learn para normalização e TensorFlow/Keras para construir o modelo.
Considere o seguinte código em Python:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from tensorflow import keras
# 1. Carregar os dados
df = pd.DataFrame({
"feature1": [10, 20, 30, 40, 50],
"feature2": [5, 15, 25, 35, 45],
"target": [100, 200, 300, 400, 500]
})
# 2. Selecionar apenas as colunas de entrada (features)
X = df[["feature1", "feature2"]]
y = df["target"]
# 3. Normalizar os dados de entrada
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
# 4. Criar um modelo de rede neural para regressão
modelo = keras.Sequential([
keras.Input(shape=(X_scaled.shape[1],)), # Definir a camada de entrada explicitamente
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(8, activation='relu'),
tf.keras.layers.Dense(1, activation='linear') # Saída contínua
])
# 5. Compilar e treinar o modelo
modelo.compile(optimizer='adam', loss='mse')
modelo.fit(X_scaled, y, epochs=10, batch_size=2, verbose=0)Com base no código apresentado, assinale a alternativa correta sobre a execução e o comportamento desse modelo.
Provas
Considere os dois trechos de código a seguir, ambos escritos na Linguagem R. O primeiro utiliza o pacote tidyverse, enquanto o segundo utiliza caret para o mesmo propósito.
Código 1 (tidyverse)
library(tidyverse)
set.seed(123)
dados <- tibble(
X1 = rnorm(100),
X2 = rnorm(100),
Y = sample(c("A", "B"), 100, replace = TRUE)
)
dados_treino <- dados %>% sample_frac(0.7)
dados_teste <- anti_join(dados, dados_treino)Código 2 (carret)
library(caret)
set.seed(123)
dados <- data.frame(
X1 = rnorm(100),
X2 = rnorm(100),
Y = sample(c("A", "B"), 100, replace = TRUE)
)
indices <- createDataPartition(dados$Y, p = 0.7,
list = FALSE)
dados_treino <- dados[indices, ]
dados_teste <- dados[-indices, ]Em relação aos códigos apresentados, assinale a alternativa correta.
Provas
Uma empresa está implementando uma estratégia de Business Intelligence (BI) para melhorar a análise de seus dados operacionais. Para isso, a equipe de dados precisa criar dashboards interativos e realizar análises avançadas usando Power BI e Tableau.
Durante o desenvolvimento dos relatórios, os analistas se depararam com os seguintes desafios:
• Precisam criar uma métrica personalizada para calcular a média ponderada de preços com base no volume de vendas.
• Desejam otimizar o tempo de carregamento ao lidar com milhões de registros armazenados em um banco de dados relacional.
• Precisam implementar um filtro dinâmico que permita ao usuário selecionar intervalos de datas personalizados sem afetar cálculos em outros gráficos.
Com base nos desafios acima, assinale a alternativa que apresenta as melhores soluções utilizando as funcionalidades nativas do Power BI e do Tableau.
Provas
Uma rede de supermercados deseja entender os padrões de compra dos clientes para organizar melhor seus produtos e otimizar suas estratégias de vendas. Para isso, a equipe de análise de dados decidiu utilizar um algoritmo de descoberta de regras de associação para identificar itens, frequentemente, comprados juntos.
Assinale a alternativa que representa a métrica fundamental para avaliar a relevância de uma regra de associação.
Provas
Em aprendizado de máquina, classificadores binários e multiclasses são usados para categorizar dados em duas ou mais classes. Considere os cenários a seguir:
1. Um sistema de detecção de fraudes bancárias, onde cada transação deve ser classificada como fraudulenta ou não fraudulenta.
2. Um modelo de classificação de espécies de flores, onde cada flor pode ser categorizada como setosa, versicolor ou virginica.
Em relação aos cenários apresentados, assinale a alternativa que descreve os modelos mais adequados para cada tipo de problema.
Provas
Uma empresa deseja implementar uma arquitetura de dados robusta para dar suporte à análise e ao processamento diário de informações. A empresa já possui um sistema de OLTP, mas agora precisa de uma solução de OLAP para análise histórica e de tendências. Além disso, a equipe de TI está considerando a criação de Data Marts para áreas de marketing, vendas e finanças, com o objetivo de melhorar a tomada de decisões.
Com base no cenário apresentado, assinale a alternativa que melhor descreve a relação entre Data Marts, OLTP e OLAP.
Provas
A Inteligência Artificial tem sido amplamente utilizada para personalizar o ensino e otimizar diagnósticos médicos. No entanto, seu uso pode gerar efeitos adversos inesperados, especialmente em contextos de desigualdade social.
Considerando as implicações éticas e práticas da IA em setores essenciais, qual abordagem representa um uso responsável da tecnologia?
Provas
Provas
Como exemplo, considere a Árvore de Decisão (fictícia), a seguir, que classifica pacientes com base no risco de ter um infarto. As decisões são feitas com base em três critérios: idade, peso e se é fumante, ou não.
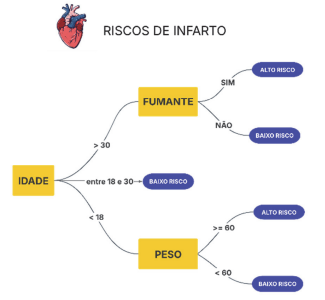
Em relação ao funcionamento das Árvores de Decisão, assinale a alternativa que descreve seu princípio de operação e comportamento na modelagem de dados.
Provas
Provas
Caderno Container