Foram encontradas 3.020 questões.
No campo da saúde, é comum a adoção de métodos
para a reduzir a dimensionalidade dos dados, como a
segmentação de idades em faixas etárias. O comando
Python, com o uso da biblioteca Pandas (pd), que pode ser
utilizado para segmentar os valores de uma lista de idades
(tipo inteiro) em 10 faixas etárias, é:
Provas
Questão presente nas seguintes provas
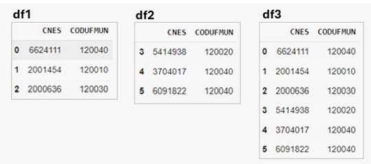
Para reproduzir a transformação ilustrada na figura
abaixo, o código Python que faz uso da bilblioteca Pandas
(pd) e pode ser utilizado para para unir dois dataframes
(df1 e df2), criando o dataframe (df3), é:
Provas
Questão presente nas seguintes provas
Dataframes da biblioteca Pandas no Python são muito
versáteis. Com eles é possível ler, processar, transformar e
exportar dados tabulares com grande eficiência. Considere
um dataframe criado a partir da leitura de um arquivo do tipo
csv (comma separated value). Só devem ser carregadas
as primeiras mil linhas das colunas A, B e C. Além disso,
todos os valores devem ser convertidos para o tipo string.
Os parâmetros e valores do método read_csv() que possibilitam isso são:
Provas
Questão presente nas seguintes provas
Um grupo de pesquisadores deseja acompanhar o
histórico de internações hospitalares de mães nascidas
após o ano 1997 e que tiveram filhos com baixo peso ao
nascer. A ideia central é identificar agravos de saúde que
podem contribuir para o baixo peso das crianças no momento do parto. Para isso, os pesquisadores pretendem
utilizar duas bases de dados disponíveis para download no
DATASUS em acesso aberto: o Sistema de Informações sobre Nascidos Vivos (SINASC) e o Sistema de Informações
Hospitalares (SIH/SUS). A pesquisa analisará os dados de
nascimentos e internações hospitalar entre 2012 e 2022.
Das opções abaixo, o real motivo que impede o desenvolvimento desse projeto é:
Das opções abaixo, o real motivo que impede o desenvolvimento desse projeto é:
Provas
Questão presente nas seguintes provas
Sobre o direito à saúde previsto na Lei Orgânica da
Saúde (Lei nº 8080/1990) e na Constituição Federal (1988),
avalie se são verdadeiras (V) ou falsas (F) as afirmativas
a seguir:
I. A saúde é um direito fundamental do ser humano, devendo o Estado, sempre que possível, prover as condições indispensáveis ao seu pleno exercício.
II. O dever do Estado não exclui o das pessoas, da família, das empresas e da sociedade.
III. A saúde é direito de todos e dever do Estado, garantido mediante políticas sociais e econômicas que visem à redução do risco de doença.
As afirmativas I, II e III são, respectivamente:
I. A saúde é um direito fundamental do ser humano, devendo o Estado, sempre que possível, prover as condições indispensáveis ao seu pleno exercício.
II. O dever do Estado não exclui o das pessoas, da família, das empresas e da sociedade.
III. A saúde é direito de todos e dever do Estado, garantido mediante políticas sociais e econômicas que visem à redução do risco de doença.
As afirmativas I, II e III são, respectivamente:
Provas
Questão presente nas seguintes provas
Segundo a Lei Orgânica da Saúde (Lei nº 8080/1990),
os serviços públicos de saúde e os serviços privados
contratados ou conveniados que integram o Sistema Único
de Saúde (SUS) devem obedecer aos princípios abaixo,
EXCETO:
Provas
Questão presente nas seguintes provas
Considerando a definição, pilares e objetivos da Saúde
Coletiva, avalie se são verdadeiras (V) ou falsas (F) as
afirmativas a seguir:
I. A saúde é definida como ausência de doenças.
II. Tem como característica ações isoladas da Vigilância Epidemiológica e Sanitária.
II. É considerada a influência de fatores sociais, econômicos e culturais na saúde das comunidades.
As afirmativas I, II e III são, respectivamente:
I. A saúde é definida como ausência de doenças.
II. Tem como característica ações isoladas da Vigilância Epidemiológica e Sanitária.
II. É considerada a influência de fatores sociais, econômicos e culturais na saúde das comunidades.
As afirmativas I, II e III são, respectivamente:
Provas
Questão presente nas seguintes provas
Disseminados pelo DATASUS para download (ftp.datasus.gov.br), os dados desagregados sobre a declaração de
óbito do Sistema de Informação sobre Mortalidade (SIM)
estão disponíveis com a extensão:
Provas
Questão presente nas seguintes provas
O Departamento de Informática do Sistema Único de
Saúde (DATASUS) disponibiliza inúmeros arquivos para
o enriquecimento das bases de dados disponíveis para
download. Alguns atributos são preenchidos com informações da classificação estatística internacional de doenças
e problemas relacionados com a Saúde (CID-10). São
disponibilizados pelo DATASUS arquivos que permitem a
agregação das doenças em:
Provas
Questão presente nas seguintes provas
Você é um cientista de dados incumbido de desenvolver
uma aplicação de perguntas e respostas para facilitar a
extração de informações de documentos PDF contendo
artigos científicos na área da saúde. Para construir essa
aplicação, as seguintes estratégias foram apresentadas.
I. Utilizar a técnica de embeddings de texto para converter documentos PDF em vetores e armazená-los em um vectorstore, como ChromaDb ou Pinecone, permitindo buscas semânticas rápidas e eficientes baseadas no conteúdo dos artigos.
II. Desenvolver um sistema de indexação baseado em metadados extraídos dos documentos PDF, como autor, data de publicação e palavras-chave, para facilitar a filtragem e a busca por documentos específicos.
III. Implementar uma abordagem de processamento de linguagem natural (PLN) que empregue a API do modelo de linguagem para gerar respostas precisas às perguntas, utilizando os vetores e metadados armazenados para recuperar informações relevantes dos documentos e inseri-las no contexto do prompt.
IV. Realizar o fine-tuning do modelo de linguagem através de um dataset que contenha o conhecimento do domínio que se quer adicionar ao modelo, utilizando frameworks como LoRA ou QLoRA para fazer o merge desse dataset adicional treinado.
V. Criar uma hierarquia de documentos baseada na classificação dos artigos científicos por tópicos e subtópicos, utilizando algoritmos de clustering para organizar automaticamente os documentos em categorias relevantes.
Das estratégias acima:
I. Utilizar a técnica de embeddings de texto para converter documentos PDF em vetores e armazená-los em um vectorstore, como ChromaDb ou Pinecone, permitindo buscas semânticas rápidas e eficientes baseadas no conteúdo dos artigos.
II. Desenvolver um sistema de indexação baseado em metadados extraídos dos documentos PDF, como autor, data de publicação e palavras-chave, para facilitar a filtragem e a busca por documentos específicos.
III. Implementar uma abordagem de processamento de linguagem natural (PLN) que empregue a API do modelo de linguagem para gerar respostas precisas às perguntas, utilizando os vetores e metadados armazenados para recuperar informações relevantes dos documentos e inseri-las no contexto do prompt.
IV. Realizar o fine-tuning do modelo de linguagem através de um dataset que contenha o conhecimento do domínio que se quer adicionar ao modelo, utilizando frameworks como LoRA ou QLoRA para fazer o merge desse dataset adicional treinado.
V. Criar uma hierarquia de documentos baseada na classificação dos artigos científicos por tópicos e subtópicos, utilizando algoritmos de clustering para organizar automaticamente os documentos em categorias relevantes.
Das estratégias acima:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container