Foram encontradas 1.195 questões.
Uma das métricas mais comumente utilizadas para
comparar resultados de algoritmos de clusterização é
obtida por meio da fórmula (b-a)/ max(a,b), em que:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
Provas
Questão presente nas seguintes provas
Seja a matriz de confusão obtida na avaliação de
desempenho de um modelo de aprendizado treinado para
classificar processos julgados pelo TJ-AC:

Os valores da performance geral, da sensibilidade e da precisão do modelo são, respectivamente:
Os valores da performance geral, da sensibilidade e da precisão do modelo são, respectivamente:
Provas
Questão presente nas seguintes provas
Observe o gráfico a seguir.
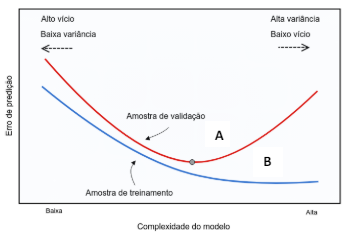
Disponível em: <http://cursos.leg.ufpr.br/ML4all/apoio/reamostragem.html>. Acesso em: mar. 2024.
O gráfico representa as regiões de overfitting e underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina com o erro de predição. A partir do exposto no gráfico, o erro de generalização do modelo ocorre na região:
Disponível em: <http://cursos.leg.ufpr.br/ML4all/apoio/reamostragem.html>. Acesso em: mar. 2024.
O gráfico representa as regiões de overfitting e underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina com o erro de predição. A partir do exposto no gráfico, o erro de generalização do modelo ocorre na região:
Provas
Questão presente nas seguintes provas
Para classificar os processos tramitados no TJ-AC em
duas categorias (deferidos e indeferidos), um analista
escolheu um algoritmo que divide os dados de entrada em
duas regiões separadas por uma linha e resulta em uma
simetria na classificação, de forma que o ponto mais
próximo de cada classe está a uma distância d do ponto
médio entre os dois grupos de classe (hiperplano). O
algoritmo descrito é denominado:
Provas
Questão presente nas seguintes provas
O ecossistema Hadoop se refere aos vários componentes
da biblioteca de software Apache Hadoop, incluindo
projetos de código aberto e ferramentas complementares
para armazenar e processar Big Data. Algumas das
ferramentas mais conhecidas incluem HDFS, Pig, YARN,
MapReduce, Spark, HBase Oozie, Sqoop e Kafka, cada
uma com função específica no ecossistema Hadoop. São
funções dos componentes do ecossistema Hadoop:
Provas
Questão presente nas seguintes provas
Naive Bayes é um método probabilístico de aprendizado
de máquina que utiliza as frequências das ocorrências em
uma base de dados para prever uma variável de interesse.
O algoritmo a ser implementado depende da natureza dos
dados manipulados. O tipo de algoritmo Naive Bayes para
processar um conjunto de dados que possui apenas
atributos categóricos codificados em one-hot é:
Provas
Questão presente nas seguintes provas
O aprendizado de máquina (do inglês, machine learning) é
um conjunto de técnicas da ciência de dados que permite
que os computadores usem os dados existentes para
prever comportamentos, resultados e tendências. Uma das
formas de classificar o aprendizado é em razão da
natureza do sinal de entrada ou feedback do processo. As
árvores de decisão, agrupamento e regras de associação
são, respectivamente, técnicas de aprendizado de
máquina:
Provas
Questão presente nas seguintes provas
Apache Hadoop é o principal framework utilizado no
processamento e armazenamento de grandes conjuntos de
dados (Big Data). No ecossistema Apache Hadoop, além
dos componentes básicos, diversas ferramentas e serviços
suprem necessidades de negócios, aplicações e
arquitetura de dados. O sistema de agendamento de
WorkFlow para gerenciar os jobs de computação
distribuída do MapReduce é o:
Provas
Questão presente nas seguintes provas
- Servidor de Arquivos e ImpressãoNFS
- WindowsServiços de Rede no Windows
- WindowsWindows ServerWindows Server 2019
No Windows Server 2019, o comando que permite exibir
ou redefinir as contagens de chamadas feitas ao servidor
para Network File System (NFS) é o:
Provas
Questão presente nas seguintes provas
No Ubuntu 22.04 servidor, o comando utilizado para monitorar
o status de memória virtual é o:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container