Foram encontradas 1.195 questões.
As características inerentes ao Big Data implicam a
necessidade de um sistema de armazenamento,
gerenciamento e análise que seja flexível, de forma a se
adaptar facilmente aos dados sem comprometer o
desempenho. Dentre as soluções, o Data Warehouse (DW)
tem como características:
Provas
Questão presente nas seguintes provas
No processo de otimização de redes neurais artificiais,
diferentes métodos e técnicas são utilizados para
determinar os melhores parâmetros do aprendizado. Para
reduzir o overfitting, uma das técnicas amplamente
utilizadas é a regularização, que apresenta como
características:
Provas
Questão presente nas seguintes provas
Considere a sentença a seguir.
s: “O acesso ao auditório também pode ser feito através de uma rampa”
Aplicando a função f à sentença, obtém-se o seguinte resultado:
f(s) = “acesso auditório pode ser feito através rampa”
A tarefa de tratamento de dados textuais realizada pela função f é:
s: “O acesso ao auditório também pode ser feito através de uma rampa”
Aplicando a função f à sentença, obtém-se o seguinte resultado:
f(s) = “acesso auditório pode ser feito através rampa”
A tarefa de tratamento de dados textuais realizada pela função f é:
Provas
Questão presente nas seguintes provas
PV-DM (do inglês, Paragraph Vector Distributed Memory) é
um método de aprendizado de máquina utilizado no
processamento de dados textuais. A ideia central é prever
uma palavra (de contexto) a partir de um conjunto de
palavras amostrado aleatoriamente – palavras de contexto
e ID de parágrafo. Quando aplicado sobre um conjunto de
documentos textuais (por exemplo, os processos deferidos
arquivados no TJ-AC), qual a vantagem desse método em
relação ao método BOW, baseado em contagem de
palavras?
Provas
Questão presente nas seguintes provas
Para reduzir a dimensionalidade de um conjunto de dados
bidimensionais, foi executado o algoritmo PCA (do inglês,
Principal Component Analysis). Se o PCA produzir como
resultado dois autovalores de mesmo valor, significa que
Provas
Questão presente nas seguintes provas
A árvore de decisão ilustrada a seguir foi modelada com
base nos dados de registros de ocorrência da dengue no
estado do Acre nos últimos cinco (5) anos e será utilizada
para tomada de decisão acerca da priorização na
disponibilização de vacinas.
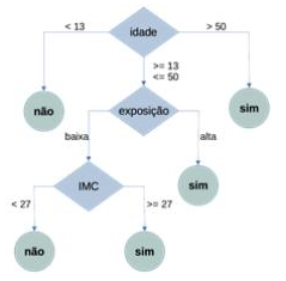
Qual é a evidência de que esse modelo foi construído usando o algoritmo C4.5 ou suas variantes, e não usando o ID3?
Qual é a evidência de que esse modelo foi construído usando o algoritmo C4.5 ou suas variantes, e não usando o ID3?
Provas
Questão presente nas seguintes provas
O pré-processamento é um conjunto de atividades que
envolvem preparação, organização e estruturação de
dados, sendo fundamental no desempenho do modelo de
aprendizagem de máquina. Tais atividades contemplam
métodos e técnicas de limpeza, transformação, integração
e redução de dimensionalidade. Os métodos que podem
ser utilizados para o tratamento de dados faltantes são:
Provas
Questão presente nas seguintes provas
Random Forest são algoritmos de aprendizado de máquina
utilizados para classificação ou regressão, sendo vantajoso
em relação às árvores de decisão no caso de
Provas
Questão presente nas seguintes provas
A camada de uma rede convolucional que tem como
função primária reduzir progressivamente o tamanho
espacial do volume de dados de entrada por meio do
mapeamento de seções de features e diminuição dos
pesos de treinamento é denominada camada de
Provas
Questão presente nas seguintes provas
Uma rede neural foi implementada a partir da arquitetura
Multilayer Perceptron (MLP) e o conjunto de dados foi
dividido em holdout com 50% para conjunto de
treinamento, 30% para conjunto de validação e 20% para
conjunto de teste. Se, durante o treinamento e a validação
da referida rede ocorreu underfitting, dois fatores que
podem ter condicionado tal fenômeno são:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container