Foram encontradas 560 questões.
De acordo com a Pesquisa IA no Poder Judiciário 2024, realizada
pelo Conselho Nacional de Justiça (CNJ) em parceria com o
Programa das Nações Unidas para o Desenvolvimento (PNUD), o
desenvolvimento de soluções de IA tornou-se uma realidade
dentro dos tribunais e conselhos do Poder Judiciário, em grande
parte para superar desafios do cotidiano de trabalho, em especial
por meio da automação de dados.
A integração de práticas do ITIL 4 para automação de dados contribui para:
A integração de práticas do ITIL 4 para automação de dados contribui para:
Provas
Questão presente nas seguintes provas
A assessoria de inteligência artificial do Tribunal de Justiça do
Estado do Rio de Janeiro quer criar um assistente jurídico,
utilizando modelos de inteligência artificial generativa, para
apoiar juízes na elaboração de decisões e minutas de sentenças
para processos judiciais.
De acordo com os princípios do COBIT® 2019, para garantir a qualidade dos dados analíticos, um sistema de governança deve:
De acordo com os princípios do COBIT® 2019, para garantir a qualidade dos dados analíticos, um sistema de governança deve:
Provas
Questão presente nas seguintes provas
Uma equipe de ciência de dados está desenvolvendo um modelo
de classificação de inadimplência em um conjunto de dados
tabular com informações numéricas e categóricas de clientes
(renda, idade, histórico de crédito, limite etc.).
O conjunto está fortemente desbalanceado: apenas 3% dos registros pertencem à classe denominada inadimplente. O time deseja aumentar a quantidade de exemplos da classe minoritária sem simplesmente duplicar registros existentes, gerando novas amostras sintéticas entre os pontos reais da classe positiva, para reduzir o risco de overfitting associado ao oversampling ingênuo.
A técnica de balanceamento de classes adequada para esse cenário é:
O conjunto está fortemente desbalanceado: apenas 3% dos registros pertencem à classe denominada inadimplente. O time deseja aumentar a quantidade de exemplos da classe minoritária sem simplesmente duplicar registros existentes, gerando novas amostras sintéticas entre os pontos reais da classe positiva, para reduzir o risco de overfitting associado ao oversampling ingênuo.
A técnica de balanceamento de classes adequada para esse cenário é:
Provas
Questão presente nas seguintes provas
Um laboratório de pesquisa médica está desenvolvendo um
sistema de inteligência artificial para auxiliar no diagnóstico de
uma doença de pele extremamente rara. O maior desafio do
projeto é a escassez de dados: a equipe possui apenas
300 imagens dermatoscópicas rotuladas da doença, quantidade
insuficiente para treinar uma rede neural convolucional (CNN)
complexa do zero sem causar sobreajuste (overfitting).
Para contornar essa limitação, os cientistas de dados decidiram utilizar um modelo de arquitetura robusta (como a ResNet-50), que já foi previamente treinado em milhões de imagens genéricas do banco de dados ImageNet. A estratégia adotada consiste em manter os pesos das camadas iniciais da rede inalterados (congelados), aproveitando a capacidade do modelo de reconhecer formas e texturas, e treinar apenas as últimas camadas para distinguir a lesão de pele específica.
Essa técnica de reaproveitamento de conhecimento prévio de um domínio para resolver um problema em outro domínio com poucos dados é denominada:
Para contornar essa limitação, os cientistas de dados decidiram utilizar um modelo de arquitetura robusta (como a ResNet-50), que já foi previamente treinado em milhões de imagens genéricas do banco de dados ImageNet. A estratégia adotada consiste em manter os pesos das camadas iniciais da rede inalterados (congelados), aproveitando a capacidade do modelo de reconhecer formas e texturas, e treinar apenas as últimas camadas para distinguir a lesão de pele específica.
Essa técnica de reaproveitamento de conhecimento prévio de um domínio para resolver um problema em outro domínio com poucos dados é denominada:
Provas
Questão presente nas seguintes provas
Um cientista de dados treinou três modelos para prever evasão
escolar usando dados de 12.000 alunos de 2019-2023: Random
Forest, XGBoost e Regressão Logística. Para avaliar os modelos,
dividiu o dataset em 70% treino e 30% teste, treinou cada
modelo no conjunto de treino e reportou as seguintes acurácias
no teste: RF=89%, XGBoost=91%, Logística=82%.
Com base nesses resultados, foi recomendado o XGBoost para
produção.
A avaliação dessa metodologia de validação é:
A avaliação dessa metodologia de validação é:
Provas
Questão presente nas seguintes provas
Diferentes sistemas produzem dados em formatos variados, que
podem ser classificados em dados estruturados,
semiestruturados ou não estruturados.
Nesse contexto, relacione os tipos de dados às suas respectivas descrições.
1. Dados estruturados
2. Dados semiestruturados
3. Dados não estruturados
( ) Gravações em áudio e vídeo de audiências públicas, armazenadas em arquivos MP4, acompanhadas apenas de nome do arquivo e data de criação.
( ) Registros de protocolo eletrônico armazenados em tabelas de banco de dados relacional, com campos bem definidos (número do processo, data, unidade, assunto) e chaves primárias/estrangeiras.
( ) Arquivos de log de acesso ao portal de serviços do governo, registrados em formato JSON, contendo campos como timestamp, user_id, endpoint, status_code, com alguns campos opcionais variando conforme o tipo de requisição.
A sequência correta é:
Nesse contexto, relacione os tipos de dados às suas respectivas descrições.
1. Dados estruturados
2. Dados semiestruturados
3. Dados não estruturados
( ) Gravações em áudio e vídeo de audiências públicas, armazenadas em arquivos MP4, acompanhadas apenas de nome do arquivo e data de criação.
( ) Registros de protocolo eletrônico armazenados em tabelas de banco de dados relacional, com campos bem definidos (número do processo, data, unidade, assunto) e chaves primárias/estrangeiras.
( ) Arquivos de log de acesso ao portal de serviços do governo, registrados em formato JSON, contendo campos como timestamp, user_id, endpoint, status_code, com alguns campos opcionais variando conforme o tipo de requisição.
A sequência correta é:
Provas
Questão presente nas seguintes provas
Um tribunal deseja prever o tempo de tramitação (em dias) de processos de uma determinada classe, desde a distribuição até a sentença em 1ª instância. Um cientista de dados ajustou um modelo de regressão usando variáveis como tipo de ação, vara, quantidade de partes e histórico de movimentações, e avaliou o modelo no conjunto de teste.
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
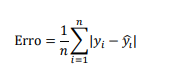
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é:
Provas
Questão presente nas seguintes provas
Uma fintech desenvolveu um pipeline ponta a ponta (end-to-end)
de machine learning para detecção de fraudes em transações
financeiras.
O pipeline inclui as seguintes etapas:
(1) ingestão de dados em tempo real via streaming;
(2) feature engineering com agregações temporais (médias móveis de 7 e 30 dias);
(3) predição usando um modelo de gradient boosting;
(4) deployment em arquitetura de microsserviços.
Após três meses em produção, o time de MLOps observou degradação gradual no F1-score de 0.89 para 0.72, enquanto o monitoramento revelou que as distribuições das features agregadas apresentavam mudanças estatisticamente significativas (p < 0.01 no teste de Kolmogorov-Smirnov), embora as features brutas individuais permanecessem estáveis.
Considerando as melhores práticas de pipelines de ML em produção e estratégias de deployment, a equipe deve:
O pipeline inclui as seguintes etapas:
(1) ingestão de dados em tempo real via streaming;
(2) feature engineering com agregações temporais (médias móveis de 7 e 30 dias);
(3) predição usando um modelo de gradient boosting;
(4) deployment em arquitetura de microsserviços.
Após três meses em produção, o time de MLOps observou degradação gradual no F1-score de 0.89 para 0.72, enquanto o monitoramento revelou que as distribuições das features agregadas apresentavam mudanças estatisticamente significativas (p < 0.01 no teste de Kolmogorov-Smirnov), embora as features brutas individuais permanecessem estáveis.
Considerando as melhores práticas de pipelines de ML em produção e estratégias de deployment, a equipe deve:
Provas
Questão presente nas seguintes provas
Uma empresa de e-commerce implantou um modelo de machine learning para prever a probabilidade de churn, métrica que indica a rotatividade ou evasão de clientes. Após seis meses em produção, a equipe de dados observou que, embora as distribuições estatísticas das features de entrada permanecessem estáveis (mesmas médias, mesmos desvios-padrão e mesmas distribuições), o relacionamento entre essas features e a variável-alvo (churn) havia mudado significativamente devido a alterações no comportamento dos consumidores causadas por novas políticas de fidelização da empresa.
Diante desse cenário, é correto afirmar que o modelo:
Diante desse cenário, é correto afirmar que o modelo:
Provas
Questão presente nas seguintes provas
O desempenho de modelos de aprendizado de máquina está intrinsecamente relacionado ao equilíbrio entre viés e variância. Modelos com alto viés tendem a simplificar excessivamente o problema, resultando em subajuste (underfitting), enquanto modelos com alta variância podem capturar ruído nos dados de treinamento, levando ao sobreajuste (overfitting). Para mitigar esses problemas, diversas técnicas de regularização podem ser empregadas, ajustando a complexidade do modelo e melhorando sua capacidade de generalização.
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container