Foram encontradas 5.009 questões.
Bernardo, analista de dados do TRF-1, realiza o pré-processamento de um dataset que será utilizado para treinar o chatbot do Tribunal. Em uma das etapas do pré-processamento, ele utiliza uma ferramenta que deflexiona as palavras, retirando suas inflexões.
Nessa etapa, Bernardo realizou uma:
Provas
Nas técnicas de agrupamento hierárquico, é necessário estabelecer uma abordagem para calcular a similaridade entre dois clusters.
A abordagem que utiliza como medida a maior distância de um ponto do primeiro cluster para um ponto do segundo cluster é chamada de ligação:
Provas
Anderson, analista de dados do TRF-1, gerou a matriz de confusão abaixo a partir dos resultados obtidos com um classificador binário.
|
Previsto |
|||
| Classe 1 |
Classe 2 |
||
|
Real |
Classe 1 | 80 | 30 |
|
Classe 2 |
10 | 40 | |
Ao calcular a F1-score ponderada para esse classificador, Anderson obteve o valor:
Provas
A analista Ana está implementando um script para deep learning utilizando o Python e o PyTorch. Considere o seguinte trecho do script de Ana:
import torch
import torch.nn.functional as F
input = torch.randn(3, 5, requires_grad=True)
target = torch.tensor([1, 2, 0])
loss_fn = F.nll_loss
loss = loss_fn(F.log_softmax(input, dim=1), target)
print(loss)
Ao ser executado, o trecho do script acima irá:
Provas
Considere o seguinte código em Python com NumPy:
import numpy as np
a = np.arange(16).reshape(8,2).T
print(a.shape, a.ndim, a[0][1])
Ao ser executado, o código acima imprime na saída padrão:
Provas
Em aplicações modernas de Processamento de Linguagem Natural, usando Grandes Modelos de Linguagem (Large Language Models – LLM) é comum a necessidade de usar informações relevantes que estão em documentos novos e privados, que não foram usados no pré-treinamento dos modelos de LLM. Considerando que esses documentos podem ser longos e em grande quantidade, que o tamanho do contexto usado na chamada à Application Programming Interface (API) da LLM é limitado, e ainda pensando que os custos de processar são muitas vezes calculados por quantidade de tokens, foi desenvolvida a técnica conhecida como Retrieval Augmented Generation (RAG).
Considerando-se esse contexto, qual é a característica da técnica RAG?
Provas
Um cientista de dados está utilizando SHapley Additive exPlanations (SHAP) para entender a importância das variáveis em um modelo de aprendizado de máquina que prevê a probabilidade de um cliente deixar de ser assinante de um serviço (churn). Considere o seguinte conjunto de dados simplificado com três características para um cliente específico:
|
Característica |
Valor |
Contribuição Marginal ao Modelo – Valor de Shapley |
|
Tempo de |
12 (meses) |
0,05 |
|
Número de |
3 | 0,20 |
|
Número de |
10 | 0,15 |
A previsão base do modelo, que representa a probabilidade estimada de um cliente se tornar um churn quando nenhuma das características individuais é considerada, é de 0,30.
Considerando-se esse contexto, qual é a probabilidade prevista pelo modelo para que esse cliente deixe de assinar o serviço?
Provas
Um pesquisador de ciência de dados foi encarregado de analisar a capacidade de um modelo de aprendizado de máquina em prever se um cliente é bom pagador. Para isso, possuía um conjunto de dados de testes rotulado, sobre o qual aplicou o modelo e obteve a matriz de confusão a seguir:
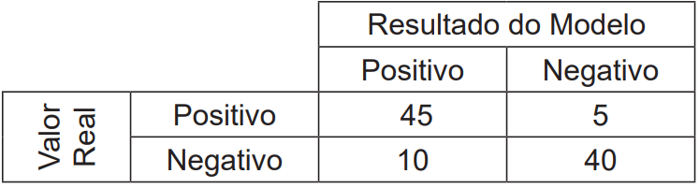
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Provas
Uma empresa está desenvolvendo um dashboard interativo para monitorar o desempenho das vendas em tempo real. O objetivo é fornecer uma visão clara e acessível para diferentes níveis de usuários, desde gerentes executivos até analistas de dados. Foram definidos os seguintes requisitos:
1. Os dados de vendas precisam ser visualizados por região, produto e período de tempo.
2. O dashboard deve permitir aos usuários explorar dados específicos por meio de interações como filtros e drill-downs.
3. A organização dos elementos visuais deve ser intuitiva, priorizando informações críticas e mantendo um layout claro e acessível.
Com base nas boas práticas de design de dashboards, qual abordagem deve ser adotada para garantir que o dashboard seja eficaz e acessível para todos os usuários?
Provas
Uma equipe precisa apresentar os resultados de diversas análises para diferentes públicos. Cada visualização deve ser escolhida e projetada de forma a comunicar claramente os insights obtidos, considerando as boas práticas de design e de acessibilidade.
Serão apresentados, em momentos diferentes, os seguintes dados:
1. Distribuição de idades de uma pesquisa populacional, que possui um grande número de participantes.
2. Comparação de receitas mensais de diferentes setores de uma empresa ao longo de um ano.
3. Proporção de vendas de diferentes produtos de uma loja durante o último trimestre.
4. Análise de correlação entre as variáveis “horas de estudo” e “nota final” de estudantes.
Considerando-se as boas práticas de design e acessibilidade, quais tipos de gráficos devem ser utilizados para a visualização dessas quatro situações?
Provas
Caderno Container