Foram encontradas 295 questões.
A sequência a seguir foi criada com um padrão lógico-matemático:
1, 2, 3, 4, 5, 6, 7, 2, 4, 6, 8, 10, 12, 14, 3, 6, 9, 12, 15, 18, 21, 4, 8, 12, 16, 20, 24, 28, 5, …
Considerando esse padrão, é possível determinar os elementos em qualquer posição da sequência. Sejam F o 125° e G o 165° elementos dessa sequência, a razão F/G em seu formato irredutível é
1, 2, 3, 4, 5, 6, 7, 2, 4, 6, 8, 10, 12, 14, 3, 6, 9, 12, 15, 18, 21, 4, 8, 12, 16, 20, 24, 28, 5, …
Considerando esse padrão, é possível determinar os elementos em qualquer posição da sequência. Sejam F o 125° e G o 165° elementos dessa sequência, a razão F/G em seu formato irredutível é
Provas
Questão presente nas seguintes provas
Adriana, Bruna e Carla são amigas e suas idades são
35, 42 e 48 anos, não necessariamente nessa ordem.
Elas têm profissões diferentes, sendo uma delas
médica, outra advogada e outra professora. Também é
conhecido o fato de que Adriana não tem 48 anos e é
prima da médica. Já a professora mora bem perto da
Adriana, e Carla já passava dos 10 anos de idade quando a futura professora nasceu.
Com essas informações, é correto afirmar que a diferença entre a soma das idades da médica e da advogada e a soma das idades de Adriana e de Bruna é igual a
Com essas informações, é correto afirmar que a diferença entre a soma das idades da médica e da advogada e a soma das idades de Adriana e de Bruna é igual a
Provas
Questão presente nas seguintes provas
Um artesão tinha à sua disposição um bloco compacto de madeira, com formato cúbico, cujo volume era de
4.096 cm3
. Ele dividiu esse cubo, sem perda de material, em oito cubos iguais. Quatro desses cubos o artesão
desbastou até que ficassem, cada um, com o formato de
um cilindro, cuja base circular tinha diâmetro de medida
igual à aresta do cubo e cuja altura era a mesma altura
do cubo; outros três desses cubos ele desbastou até que
ficassem cada um com o formato de uma pirâmide cuja
base era uma das faces do cubo e cuja altura era igual
à altura do cubo; um desses oito cubos o artesão não
alterou.
Ao realizar esse trabalho de criação dessas oito peças, o volume de madeira que o artesão desbastou correspondia, em relação ao bloco de madeira inicial, a
Adote: π = 3
Ao realizar esse trabalho de criação dessas oito peças, o volume de madeira que o artesão desbastou correspondia, em relação ao bloco de madeira inicial, a
Adote: π = 3
Provas
Questão presente nas seguintes provas
Para realçar um discurso de sucesso, o diretor de uma
empresa quer expor os resultados positivos dos últimos
6 meses por meio de uma análise das medidas de tendência central que são: média, mediana e moda. Os
resultados a serem considerados são os totais de vendas
de cada mês, que são, respectivamente e em milhões de
reais: 23, 16, 17, 20, 8 e 16.
O diretor calculou essas três medidas que, em ordem crescente de valor, são:
O diretor calculou essas três medidas que, em ordem crescente de valor, são:
Provas
Questão presente nas seguintes provas
Uma senha de acesso a um computador é composta de
7 caracteres distintos, que são, nesta ordem: 3 letras
dentre as letras A, B, C, D e E e 4 algarismos dentre
os algarismos 1, 2, 3, 4 e 5. A primeira letra utilizada
na senha deve ser seguida de outras duas letras que
sejam, em relação à ordem alfabética, posteriores à
primeira letra, e essas outras duas letras devem estar
em ordem alfabética. O primeiro algarismo utilizado na
senha deve ser seguido de outros três algarismos que
sejam menores do que esse primeiro algarismo.
Considerando todas as possibilidades de criação dessas senhas, a probabilidade de uma delas ser sorteada e ser uma senha que inicie com a letra B e termine com o algarismo 2 é
Considerando todas as possibilidades de criação dessas senhas, a probabilidade de uma delas ser sorteada e ser uma senha que inicie com a letra B e termine com o algarismo 2 é
Provas
Questão presente nas seguintes provas
Curiosamente, a cotação anual de um ativo sofreu reajustes positivos e sucessivos de, respectivamente, 3%,
40%, 3%, 40%, 3%, 40% e 3%.
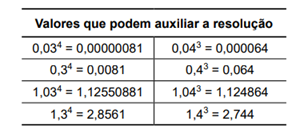
Após esses sete reajustes na cotação, é correto afirmar que o reajuste total que essa cotação sofreu foi um valor mais próximo de
Após esses sete reajustes na cotação, é correto afirmar que o reajuste total que essa cotação sofreu foi um valor mais próximo de
Provas
Questão presente nas seguintes provas
Está em conformidade com a norma-padrão de emprego
e colocação pronominal a frase:
Provas
Questão presente nas seguintes provas
Leia o texto a seguir para responder à questão:
O desenvolvimento da Inteligência Artificial Generativa
(IAG) depende do treinamento de vastos conjuntos de
informações para que o modelo aprenda sobre linguagem,
padrões e conhecimento geral. Esses dados podem incluir
textos, imagens ou vídeos, os quais frequentemente são protegidos por direitos autorais.
Se, por um lado, a criatividade e o conteúdo humano precisam ser preservados e recompensados, por outro, regras
rígidas de direitos autorais para o treinamento da IAG podem
trazer efeitos colaterais preocupantes, tais como: custos proibitivos para empresas de pequeno porte, aumentando a vantagem competitiva das grandes empresas; fuga de centros de
IA para países mais permissivos; menor precisão diante da
menor quantidade de dados; e repressão da pesquisa aberta
e concentração de inovação em ambientes fechados.
O conteúdo, enquanto obra passível de proteção, é utilizado somente como insumo técnico para ensinar o modelo
sobre as relações estatísticas entre os seus elementos.
Embora esses vetores não reproduzam diretamente a obra
original e os modelos não armazenem os dados como um
banco de referência consultável, eles podem carregar sua
estrutura em forma matemática, o que poderia levar à conclusão de que, a partir disso, seria possível reconstruir o
conteúdo protegido.
Diferentemente de um livro digital ou de uma música
arquivada, esses sistemas não guardam cada obra de forma
individual, mas extraem padrões estatísticos gerais a partir
do conjunto de uma grande massa toda. A memorização de
trechos específicos pode ocorrer, mas em pequena escala.
Em geral, o modelo generaliza e o impacto de cada obra isolada se dilui dentro da massa de dados, não havendo como
rastrear a contribuição unitária. Isso torna inadequado tratar
o treinamento desses modelos como se fosse equivalente
ao uso individualizado de uma obra musical, jornalística ou
literária.
No Brasil, há fundamentos jurídicos que permitem a aplicação do “uso justo”, conforme entendimentos do Superior
Tribunal de Justiça (STJ) sobre a Lei de Direitos Autorais,
quando: se tratar de situação especial; não prejudicar a
exploração normal da obra; e não causar dano injustificado
aos interesses do autor.
Em geral, no caso do “treinamento justo”, os argumentos
são: os dados são utilizados apenas como insumos técnicos,
para ensinar padrões estatísticos, e não para copiar as obras
originais; o aprendizado de máquina é comparável ao processo humano de indução e generalização; e a responsabilização deve ser aplicada em relação aos resultados produzidos
que violem direitos autorais.
Ou seja, o tema é desafiador e de alta complexidade,
sob a perspectiva técnica e jurídica. A tensão entre garantir
a remuneração e o reconhecimento dos criadores, por um
lado, e não inviabilizar a inovação tecnológica, por outro, exige abordagem regulatória cuidadosa, proporcional e tecnologicamente embasada.
(Rony Vainzof. Treinamento da IA, direitos autorais e regulação.
www.estadao.com.br, 21.10.2025. Adaptado)
O conteúdo, enquanto obra passível de proteção, é utilizado somente como insumo técnico para ensinar o modelo sobre as relações estatísticas entre os seus elementos. Embora esses vetores não reproduzam diretamente a obra original e os modelos não armazenem os dados como um banco de referência consultável, eles podem carregar sua estrutura em forma matemática, o que poderia levar à conclusão de que, a partir disso, seria possível reconstruir o conteúdo protegido.
Os vocábulos destacados podem ser substituídos, respectivamente, mantendo-se o sentido e a norma-padrão do trecho, por:
Provas
Questão presente nas seguintes provas
Leia o texto a seguir para responder à questão:
O desenvolvimento da Inteligência Artificial Generativa
(IAG) depende do treinamento de vastos conjuntos de
informações para que o modelo aprenda sobre linguagem,
padrões e conhecimento geral. Esses dados podem incluir
textos, imagens ou vídeos, os quais frequentemente são protegidos por direitos autorais.
Se, por um lado, a criatividade e o conteúdo humano precisam ser preservados e recompensados, por outro, regras
rígidas de direitos autorais para o treinamento da IAG podem
trazer efeitos colaterais preocupantes, tais como: custos proibitivos para empresas de pequeno porte, aumentando a vantagem competitiva das grandes empresas; fuga de centros de
IA para países mais permissivos; menor precisão diante da
menor quantidade de dados; e repressão da pesquisa aberta
e concentração de inovação em ambientes fechados.
O conteúdo, enquanto obra passível de proteção, é utilizado somente como insumo técnico para ensinar o modelo
sobre as relações estatísticas entre os seus elementos.
Embora esses vetores não reproduzam diretamente a obra
original e os modelos não armazenem os dados como um
banco de referência consultável, eles podem carregar sua
estrutura em forma matemática, o que poderia levar à conclusão de que, a partir disso, seria possível reconstruir o
conteúdo protegido.
Diferentemente de um livro digital ou de uma música
arquivada, esses sistemas não guardam cada obra de forma
individual, mas extraem padrões estatísticos gerais a partir
do conjunto de uma grande massa toda. A memorização de
trechos específicos pode ocorrer, mas em pequena escala.
Em geral, o modelo generaliza e o impacto de cada obra isolada se dilui dentro da massa de dados, não havendo como
rastrear a contribuição unitária. Isso torna inadequado tratar
o treinamento desses modelos como se fosse equivalente
ao uso individualizado de uma obra musical, jornalística ou
literária.
No Brasil, há fundamentos jurídicos que permitem a aplicação do “uso justo”, conforme entendimentos do Superior
Tribunal de Justiça (STJ) sobre a Lei de Direitos Autorais,
quando: se tratar de situação especial; não prejudicar a
exploração normal da obra; e não causar dano injustificado
aos interesses do autor.
Em geral, no caso do “treinamento justo”, os argumentos
são: os dados são utilizados apenas como insumos técnicos,
para ensinar padrões estatísticos, e não para copiar as obras
originais; o aprendizado de máquina é comparável ao processo humano de indução e generalização; e a responsabilização deve ser aplicada em relação aos resultados produzidos
que violem direitos autorais.
Ou seja, o tema é desafiador e de alta complexidade,
sob a perspectiva técnica e jurídica. A tensão entre garantir
a remuneração e o reconhecimento dos criadores, por um
lado, e não inviabilizar a inovação tecnológica, por outro, exige abordagem regulatória cuidadosa, proporcional e tecnologicamente embasada.
(Rony Vainzof. Treinamento da IA, direitos autorais e regulação.
www.estadao.com.br, 21.10.2025. Adaptado)
Provas
Questão presente nas seguintes provas
Leia o texto a seguir para responder à questão:
O desenvolvimento da Inteligência Artificial Generativa
(IAG) depende do treinamento de vastos conjuntos de
informações para que o modelo aprenda sobre linguagem,
padrões e conhecimento geral. Esses dados podem incluir
textos, imagens ou vídeos, os quais frequentemente são protegidos por direitos autorais.
Se, por um lado, a criatividade e o conteúdo humano precisam ser preservados e recompensados, por outro, regras
rígidas de direitos autorais para o treinamento da IAG podem
trazer efeitos colaterais preocupantes, tais como: custos proibitivos para empresas de pequeno porte, aumentando a vantagem competitiva das grandes empresas; fuga de centros de
IA para países mais permissivos; menor precisão diante da
menor quantidade de dados; e repressão da pesquisa aberta
e concentração de inovação em ambientes fechados.
O conteúdo, enquanto obra passível de proteção, é utilizado somente como insumo técnico para ensinar o modelo
sobre as relações estatísticas entre os seus elementos.
Embora esses vetores não reproduzam diretamente a obra
original e os modelos não armazenem os dados como um
banco de referência consultável, eles podem carregar sua
estrutura em forma matemática, o que poderia levar à conclusão de que, a partir disso, seria possível reconstruir o
conteúdo protegido.
Diferentemente de um livro digital ou de uma música
arquivada, esses sistemas não guardam cada obra de forma
individual, mas extraem padrões estatísticos gerais a partir
do conjunto de uma grande massa toda. A memorização de
trechos específicos pode ocorrer, mas em pequena escala.
Em geral, o modelo generaliza e o impacto de cada obra isolada se dilui dentro da massa de dados, não havendo como
rastrear a contribuição unitária. Isso torna inadequado tratar
o treinamento desses modelos como se fosse equivalente
ao uso individualizado de uma obra musical, jornalística ou
literária.
No Brasil, há fundamentos jurídicos que permitem a aplicação do “uso justo”, conforme entendimentos do Superior
Tribunal de Justiça (STJ) sobre a Lei de Direitos Autorais,
quando: se tratar de situação especial; não prejudicar a
exploração normal da obra; e não causar dano injustificado
aos interesses do autor.
Em geral, no caso do “treinamento justo”, os argumentos
são: os dados são utilizados apenas como insumos técnicos,
para ensinar padrões estatísticos, e não para copiar as obras
originais; o aprendizado de máquina é comparável ao processo humano de indução e generalização; e a responsabilização deve ser aplicada em relação aos resultados produzidos
que violem direitos autorais.
Ou seja, o tema é desafiador e de alta complexidade,
sob a perspectiva técnica e jurídica. A tensão entre garantir
a remuneração e o reconhecimento dos criadores, por um
lado, e não inviabilizar a inovação tecnológica, por outro, exige abordagem regulatória cuidadosa, proporcional e tecnologicamente embasada.
(Rony Vainzof. Treinamento da IA, direitos autorais e regulação.
www.estadao.com.br, 21.10.2025. Adaptado)
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container