Foram encontradas 5.012 questões.
Assinale a alternativa com as nomenclaturas que correlacionam adequadamente os conceitos a seguir.
1. Qualquer dado mantido para suportar as operações ou o uso de um Data Warehouse.
2. Repositórios de dados departamentais restritos por assunto.
3. Ferramentas que permitem a análise de dados complexos.
Provas
A utilização do modelo de dados multidimensional para modelagem de aplicações de negócio apresenta tanto aspectos estáticos quanto dinâmicos. Quanto aos aspectos dinâmicos, temse um conjunto de operações analíticas que atua sobre esses dados, a saber: drill-across, drilldown, slice and dice, roll-up, pivot. Nesse sentido, qual é a operação que permite aos usuários restringirem dados sendo analisados a um subconjunto desses dados?
Provas
Um aspecto importante na construção de um Data Warehouse é a escolha da granularidade dos dados. Com relação a esse conceito, avalie as afirmações a seguir.
1) Um maior nível de granularidade implica um acesso mais restrito aos dados.
2) A granularidade promove um impacto no volume de dados armazenados.
3) Quanto menor o nível de granularidade menor a precisão.
Assinale a alternativa que analisa corretamente as afirmações 1), 2) e 3).
Provas
Analise as características elencadas a seguir.
1) Apresenta relevância, propósito e exige necessariamente a mediação humana.
2) Exige consenso em relação ao significado e requer unidade de análise.
Essas asserções caracterizam de forma necessária e suficiente o(s) conceito(s) de
Provas
Considerando um modelo multidimensional de um data warehouse, pode ser implementado o denominado agrupamento de afinidades (ou market basket), em uma tabela fato, representando vendas de produtos, sendo correto que
Provas
A palavra cluster, do inglês, pode ser traduzida para o Português como aglomerado ou agrupamento. Na computação, essa palavra é utilizada em redes de computadores para designar o agrupamento de computadores para armazenamento e processamento de dados em software quando se busca analisar dados armazenados e que podem ser processados por técnicas de aprendizado de máquina. Nessas duas situações, é necessário identificar corretamente a quantidade de clusters que formam determinado sistema. Considerando a figura a seguir, selecione a opção que melhor representa a quantidade de clusters.
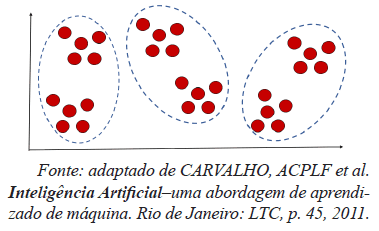
Provas
Em meio às diversas tarefas rotineiras de um Analista de Tecnologia da Informação, está a necessidade de consultar dados em Sistemas Gerenciadores de Bancos de Dados. A linguagem SQL permite a consulta de dados, em bases previamente populadas, por meio de comandos específicos. Considerando a necessidade de verificar a quantidade de registros existentes que, em determinado campo, tem seu valor iniciado com o caractere ‘a’, cite a opção que se apresenta como operador indispensável:
Provas
A biblioteca NLTK (Natural Language Toolkit) engloba ferramentas para processamento de linguagem natural, tais como funções de tokenização e radicalização. Dessa forma, considerando o código apresentado:
frase = “Não esqueçam a lista de materiais: 1 lápis e 2 canetas!”
from nltk.tokenize import RegexpTokenizer
tokenizador = RegexpTokenizer(r’w+’)
tokens = tokenizador.tokenize(frase)
print(tokens)
Qual o resultado correto?
Provas
Uma rede neural é um modelo preditivo motivado pela forma como o cérebro funciona. Redes neurais artificiais são formadas por neurônios artificiais, que desenvolvem cálculos similares sobre suas entradas. Elas podem resolver uma variedade de problemas, tais como o reconhecimento de caligrafia e a detecção facial, entre outros. São geralmente representadas por meio de um grafo orientado, onde os vértices representam os neurônios e as arestas representam as sinapses. Podem ser classificadas em três categorias específicas: Redes Neurais Feed-Forward, Redes Recorrentes e Redes Conectadas Simetricamente. Dentro dessas categorias, existem diversos tipos de arquiteturas.
Assinale a alternativa que define corretamente uma Rede Neural Perceptron Multicamadas.
Provas
O Processamento de Linguagem Natural (PLN) é a subárea da Inteligência Artificial responsável por estudar a capacidade e as limitações de uma máquina de entender a linguagem dos seres humanos. Para poder realizar essa modelagem, são necessários pré-processamentos que abstraem e estruturam a língua, deixando apenas aquilo que representa uma informação relevante. Uma das etapas desse processo compreende a normalização. Uma tarefa que pode ser realizada dentro do processo de normalização é denominada de tokenização lexical. Considere a seguinte sentença:
A área de Ciência de Dados é muito interessante!
Assinale a alternativa correta que representa o resultado da tokenização lexical para essa sentença.
Provas
Caderno Container