Foram encontradas 5.012 questões.
Dos seguintes algoritmos de aprendizado de máquina, assinale a alternativa que apresenta corretamente os algoritmos que possuem a característica
de serem de aprendizado não supervisionado.
Provas
Questão presente nas seguintes provas
Após a realização de uma pesquisa com alunos da
universidade sobre preferências em relação às
atividades acadêmicas e opções de lazer no campus, foram obtidos dados de questionários. Com
base nesses dados, isolaram-se duas variáveis
numéricas, a fim de se criarem grupos de usuários
e, posteriormente, traçarem planos específicos para
cada grupo. Arbitrariamente, foi definido que cinco
grupos distintos seriam obtidos e, posteriormente,
foi rodado um algoritmo de aprendizado de máquina
para gerar os grupos.
A partir desse contexto, duas questões foram formuladas:
(I) Qual desses algoritmos abaixo é o mais adequado para tal tarefa? (II) Qual a parametrização que deveria ter sido realizada?
Assinale a alternativa que apresenta a resposta correta para as duas questões formuladas.
A partir desse contexto, duas questões foram formuladas:
(I) Qual desses algoritmos abaixo é o mais adequado para tal tarefa? (II) Qual a parametrização que deveria ter sido realizada?
Assinale a alternativa que apresenta a resposta correta para as duas questões formuladas.
Provas
Questão presente nas seguintes provas
No contexto da implementação de tecnologias para data mining e
apresentação de dados, a sigla ETL refere-se
Provas
Questão presente nas seguintes provas
Com relação a Pytorch, assinale V para a afirmativa verdadeira e F
para a falsa.
I. Trata-se de uma biblioteca de tensores que pode ser utilizada em problemas de aprendizado profundo, podendo utilizar tanto GPU quanto CPU.
II. O pacote torch.parallel.gpu é capaz de suportar o processamento paralelo de tensores do tipo multidimensionais dimensionais e CUDA em processadores GPU.
III. O pacote torch.distributed.elasticstack é capaz distribuir um script tornando-o elástico e tolerante a falhas em diversos tipos de ambientes distribuídos.
As afirmativas são, respectivamente,
I. Trata-se de uma biblioteca de tensores que pode ser utilizada em problemas de aprendizado profundo, podendo utilizar tanto GPU quanto CPU.
II. O pacote torch.parallel.gpu é capaz de suportar o processamento paralelo de tensores do tipo multidimensionais dimensionais e CUDA em processadores GPU.
III. O pacote torch.distributed.elasticstack é capaz distribuir um script tornando-o elástico e tolerante a falhas em diversos tipos de ambientes distribuídos.
As afirmativas são, respectivamente,
Provas
Questão presente nas seguintes provas
Relacione os conceitos a seguir com suas respectivas referências
1. Business Intelligence 2. Data Warehouse 3. OLAP
A. Combina análise empresarial, mineração de dados, visualização de dados, ferramentas/infraestrutura de dados e práticas recomendadas para ajudar as organizações a tomar decisões impulsionadas por dados. As soluções modernas priorizam a análise de autoatendimento flexível, dados governados em plataformas confiáveis, a autonomia dos usuários comerciais e o acesso rápido à informação.
B. É um repositório central de informações que podem ser analisadas para propiciar a tomada de decisões mais adequadas. Os dados fluem de sistemas transacionais, bancos de dados relacionais e de outras fontes para tal repositório normalmente com uma cadência regular.
C. É um conceito de interface com o usuário que proporciona a capacidade de ter ideias sobre os dados, permitindo analisálos profundamente em diversos ângulos. Suas funções básicas são fornecer visualização multidimensional dos dados, exploração, rotação e diferentes modos de visualização; é, portanto, uma interface com o usuário e não uma forma de armazenamento de dados, porém usa o armazenamento para poder apresentar as informações.
A relação correta é
1. Business Intelligence 2. Data Warehouse 3. OLAP
A. Combina análise empresarial, mineração de dados, visualização de dados, ferramentas/infraestrutura de dados e práticas recomendadas para ajudar as organizações a tomar decisões impulsionadas por dados. As soluções modernas priorizam a análise de autoatendimento flexível, dados governados em plataformas confiáveis, a autonomia dos usuários comerciais e o acesso rápido à informação.
B. É um repositório central de informações que podem ser analisadas para propiciar a tomada de decisões mais adequadas. Os dados fluem de sistemas transacionais, bancos de dados relacionais e de outras fontes para tal repositório normalmente com uma cadência regular.
C. É um conceito de interface com o usuário que proporciona a capacidade de ter ideias sobre os dados, permitindo analisálos profundamente em diversos ângulos. Suas funções básicas são fornecer visualização multidimensional dos dados, exploração, rotação e diferentes modos de visualização; é, portanto, uma interface com o usuário e não uma forma de armazenamento de dados, porém usa o armazenamento para poder apresentar as informações.
A relação correta é
Provas
Questão presente nas seguintes provas
Analise o script abaixo
from pandas import DataFrame import matplotlib.pyplot as plt from sklearn.cluster import KMeans Data = {'x': [36,35,23,28,34,32,30,23,36,34,66,55,56,44,51,56,52,51,64,48,4 9,50,36,34,43,46,40,42,52,47],
'y':
[76,52,52,79,60,73,73,58,70,76,52,33,41,45,52,37,36,59,60,51,2 6,21,15,13,21,10,30,28,10,17] }
df = DataFrame(Data,columns=['x','y']) m = KMeans(n_clusters=3).fit(df) d = m.cluster_centers_ plt.xlabel("X") plt.ylabel("Y") plt.scatter(df['x'], df['y'], c= m.labels_.astype(float), s=100, alpha=0.5) plt.scatter(d[:, 0], d[:, 1], c='red', s=250, marker='*') plt.grid() plt.show()
O resultado da execução é
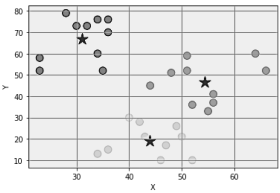
As estrelas indicam
from pandas import DataFrame import matplotlib.pyplot as plt from sklearn.cluster import KMeans Data = {'x': [36,35,23,28,34,32,30,23,36,34,66,55,56,44,51,56,52,51,64,48,4 9,50,36,34,43,46,40,42,52,47],
'y':
[76,52,52,79,60,73,73,58,70,76,52,33,41,45,52,37,36,59,60,51,2 6,21,15,13,21,10,30,28,10,17] }
df = DataFrame(Data,columns=['x','y']) m = KMeans(n_clusters=3).fit(df) d = m.cluster_centers_ plt.xlabel("X") plt.ylabel("Y") plt.scatter(df['x'], df['y'], c= m.labels_.astype(float), s=100, alpha=0.5) plt.scatter(d[:, 0], d[:, 1], c='red', s=250, marker='*') plt.grid() plt.show()
O resultado da execução é
As estrelas indicam
Provas
Questão presente nas seguintes provas
A classe da biblioteca scikit-learn, versão 1.1.2, utilizada em
scripts python para a implementação de regressão linear baseada
no método dos mínimos quadrados é
Provas
Questão presente nas seguintes provas
Nas questões que avaliem conhecimentos de informática, a menos que seja explicitamente informado o contrário, considere que: todos os programas mencionados estejam em configuração-padrão, em português; o mouse esteja configurado para pessoas destras; expressões como clicar, clique simples e clique duplo refiram-se a cliques com o botão esquerdo do mouse; e teclar corresponda à operação de pressionar uma tecla e, rapidamente, liberá-la, acionando-a apenas uma vez. Considere também que não haja restrições de proteção, de funcionamento e de uso em relação aos programas, arquivos, diretórios, recursos e equipamentos mencionados.
Provas
Questão presente nas seguintes provas
Nas questões que avaliem conhecimentos de informática, a menos que seja explicitamente informado o contrário, considere que: todos os programas mencionados estejam em configuração-padrão, em português; o mouse esteja configurado para pessoas destras; expressões como clicar, clique simples e clique duplo refiram-se a cliques com o botão esquerdo do mouse; e teclar corresponda à operação de pressionar uma tecla e, rapidamente, liberá-la, acionando-a apenas uma vez. Considere também que não haja restrições de proteção, de funcionamento e de uso em relação aos programas, arquivos, diretórios, recursos e equipamentos mencionados.
Provas
Questão presente nas seguintes provas
Considere o trecho de código abaixo escrito na linguagem Python 3.x sobre modelos preditivos de classificação usando a biblioteca scikit learn (sklearn):
from sklearn import tree
X = [[0, 0, 0], [1, 1, 1], [0, 0, 1], [1, 1, 0] ]
y = [0, 1, 0, 1]
clf = tree.DecisionTreeClassifier()
# inserir o código que irá construir/treinar o modelo classificador
Assinale a alternativa CORRETA que corresponde à linha de código que irá construir um classificador (estimador) baseado em árvores de decisão a partir do conjunto de dados de treinamento:
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container