Foram encontradas 655 questões.
Uma empresa está interessada em estudar o efeito da distribuição de cupons de desconto nas vendas de um certo produto. Desse modo, para cada nível de desconto xi, i = 1, ..., p, são escolhidas n famílias ao acaso que recebem, cada uma, um cumpom de desconto de xi reais. Algum tempo depois, determina-se o número de cupons utilizados, ri, i = 1, ..., p . Considere que !$ \pi _i !$ seja a probabilidade de que um cupom de nível xi seja utilizado. Considere também os dois modelos estatísticos seguintes para o ajuste dos dados dessa situação típica de resposta binária:
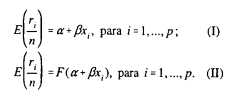
Nas expressões acima, !$ \alpha !$ e !$ \beta !$ são parâmetros e F(y) é uma função distribuição de probabilidades conhecida. Com base nessa situação hipotética, julgue o item a seguir.
Em ambos os modelos, a variância do erro independe de xi, pois o número de famílias escolhido para cada i é o mesmo.
Provas
Considere !$ \{ z_t \, : t \in Z \} !$ um processo estocástico ARIMA (0, 1, 1) satisfazendo !$ z_t-z_{t-1}=a_t- \theta a_{t-1} !$, em que !$ |\theta|<1 !$ e !$ a_t !$ são variáveis aleatórias normais, independentes e identicamente distribuídas, com média zero e variância !$ \sigma_a^2 !$. Definindo !$ w_t=z_t-z_{t-1} !$, julgue os itens abaixo.
A função de autocorrelação
!$ \rho_w(k)= {E(w_t w_{t-k}) \over E(w_t^2)} !$
satisfaz !$ |\rho (1)| < 1/2 !$ e !$ \rho _w (k)=0 !$, para !$ k>1 !$.
Provas
Um psicólogo deseja estudar o tempo (em minutos) que os empregados de uma companhia levam para realizar certa tarefa. Postula-se que os tempos na população considerada seguem uma distribuição normal com média !$ \mu !$ e variância !$ \sigma^2 !$, ambas desconhecidas. O psicólogo obteve uma amostra de !$ n = 100 !$ empregados e registrou o tempo que cada um deles precisou para realizar a tarefa. Para os 100 tempos registrados, obtiveram-se o valor médio !$ \overline {x} !$!$ = 6,25 !$ minutos e o desvio-padrão !$ s = 1 !$ minuto.
Valores selecionados da tabela normal
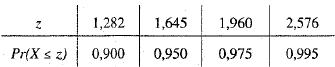
Se !$ X !$ tem distribuição normal padrão, as entradas representam a probabilidade !$ Pr (X \le z) !$.
Nessa situação e utilizando, caso seja necessário, os valores selecionados da tabela normal fornecidos acima, julgue o item a seguir.
Se o psicólogo desejar obter um intervalo de confiança de nível 95% para !$ \mu !$ cujo comprimento não seja maior que 0,04 minutos, usando como hipótese de trabalho que !$ \sigma^2 !$ !$ = 1 !$, então ele necessitará obter uma amostra de tamanho igual a 1.000.
Provas
Um psicólogo deseja estudar o tempo (em minutos) que os empregados de uma companhia levam para realizar certa tarefa. Postula-se que os tempos na população considerada seguem uma distribuição normal com média !$ \mu !$ e variância !$ \sigma^2 !$, ambas desconhecidas. O psicólogo obteve uma amostra de !$ n = 100 !$ empregados e registrou o tempo que cada um deles precisou para realizar a tarefa. Para os 100 tempos registrados, obtiveram-se o valor médio !$ \overline {x} !$!$ = 6,25 !$ minutos e o desvio-padrão !$ s = 1 !$ minuto.
Valores selecionados da tabela normal
Se !$ X !$ tem distribuição normal padrão, as entradas representam a probabilidade !$ Pr (X \le z) !$.
Nessa situação e utilizando, caso seja necessário, os valores selecionados da tabela normal fornecidos acima, julgue o item a seguir.
Para um nível de significância !$ \alpha = 0,01 !$ (ou 1%), a hipótese nula !$ H_o : \mu = 6,50 !$ é rejeitada em favor da alternativa !$ H_\alpha \, : \, \mu \, \ne \, 6,50. !$
Provas
Um auditor está interessado em estudar a relação entre consumo de gasolina − y, em litros − e distância percorrida em uma cidade − x, em quilômetros − para certo modelo· de carro. Para isso, ele obteve uma amostra de n = 25 carros e registrou a distância percorrida e o consumo de gasolina correspondente, em certo período de tempo. Considere o modelo de regressão !$ y_i = \alpha + bx_i + u_i !$, para !$ i = 1,2 ..., 25 !$, em que os erros !$ u_i !$ são independentes e normalmente distribuídos, com média !$ 0 !$ e desvio-padrão !$ \sigma_u !$, e os 25 pares de valores apresentados no gráfico abaixo.

Com relação à situação apresentada, julgue o seguinte item.
O desvio-padrão dos 25 valores de y é menor que 30 litros.
Provas
Considere X um vetor aleatório cuja distribuição !$ P_{\theta} !$ é conhecida a menos de um parâmetro real !$ \theta !$, T = T(X) uma estatística suficiente e !$ \delta=\delta(X) !$ um estimador de !$ \theta !$ com !$ E_{\theta}[L(\theta, \delta(X))] < \infty !$, em que !$ L(\theta, d) !$ é uma função perda, estritamente convexa, e !$ E_{\theta} !$ denota a esperança com respeito à distribuição !$ P_{\theta} !$. Um dos resultados fundamentais na teoria da estimação é o teorema de Rao-Blackwell, que estabelece, no contexto acima, que !$ \eta = \eta (X) !$, definido por !$ \eta (X)=E_{ \theta} [\delta(X)| T=T(x)] !$, é um estimador de !$ \theta !$ tal que, para todo !$ \theta !$
![]()
Em algumas aplicações desse teorema, utiliza-se a hipótese adicional da estatística suficiente T ser completa, o que significa que, se g é mensurável e !$ E_{\theta}[g(T)] \equiv 0 !$ , então !$ P_{\theta}(g(T)=0) \equiv 1 !$.
Com relação à situação descrita, julgue o seguinte item.
No caso particular em que !$ L( \theta, d) = ( \theta - d)^2 !$, a relação I permite concluir que
!$ Var _{\theta} ( \eta) \le Var_{\theta} (\delta) !$
para todo !$ \theta !$.
Provas
Considere !$ \{ z_t \, : t \in Z \} !$ um processo estocástico ARIMA (0, 1, 1) satisfazendo !$ z_t-z_{t-1}=a_t- \theta a_{t-1} !$, em que !$ |\theta|<1 !$ e !$ a_t !$ são variáveis aleatórias normais, independentes e identicamente distribuídas, com média zero e variância !$ \sigma_a^2 !$. Definindo !$ w_t=z_t-z_{t-1} !$, julgue os itens abaixo.
O processo !$ z_t !$ é estacionário.
Provas
Considere um modelo de duas equações simultâneas com a seguinte forma estrutural
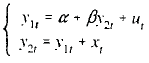
em que !$ \beta \ne 1 !$, as variáveis endógenas !$ y_{1t} !$ e !$ y_{2t} !$ e a variável exógena !$ x_t !$ são observadas para !$ t = 1,2, ..., n !$ e os erros !$ u_t !$ são variáveis aleatórias independentes com distribuição normal de média zero e variância !$ \sigma^2_u > 0. !$
Assumindo que !$ x_t !$ sejam valores fixos (não-aleatórios) e que a matriz 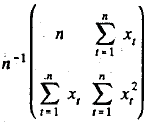 convirja a uma matriz !$ \sum !$, não singular, julgue o seguinte item.
convirja a uma matriz !$ \sum !$, não singular, julgue o seguinte item.
As equações simultâneas 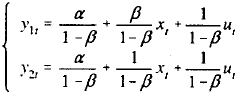 constituem a forma reduzida do modelo.
constituem a forma reduzida do modelo.
Provas
Uma empresa está interessada em estudar o efeito da distribuição de cupons de desconto nas vendas de um certo produto. Desse modo, para cada nível de desconto xi, i = 1, ..., p, são escolhidas n famílias ao acaso que recebem, cada uma, um cupom de desconto de xi reais. Algum tempo depois, determina-se o número de cupons utilizados, ri, i = 1, ..., p . Considere que !$ \pi _i !$ seja a probabilidade de que um cupom de nível xi seja utilizado. Considere também os dois modelos estatísticos seguintes para o ajuste dos dados dessa situação típica de resposta binária:
Nas expressões acima, !$ \alpha !$ e !$ \beta !$ são parâmetros e F(y) é uma função distribuição de probabilidades conhecida. Com base nessa situação hipotética, julgue o item a seguir.
Considerando o modelo II e supondo que n seja grande o suficiente para que o quociente ri / n esteja próximo de !$ \pi _i !$ e tenha distribuição essencialmente normal, então o desenvolvimento de Taylor de f(y) = F-1(y), em uma vizinhança de !$ \pi _i !$, produzirá a aproximação linear
!$ f(r_i/n)= \alpha+\beta x_i + \varepsilon _i !$
com erros normais e homocedásticos.
Provas
Uma empresa está interessada em estudar o efeito da distribuição de cupons de desconto nas vendas de um certo produto. Desse modo, para cada nível de desconto xi, i = 1, ..., p, são escolhidas n famílias ao acaso que recebem, cada uma, um cupom de desconto de xi reais. Algum tempo depois, determina-se o número de cupons utilizados, ri, i = 1, ..., p . Considere que !$ \pi _i !$ seja a probabilidade de que um cupom de nível xi seja utilizado. Considere também os dois modelos estatísticos seguintes para o ajuste dos dados dessa situação típica de resposta binária:
Nas expressões acima, !$ \alpha !$ e !$ \beta !$ são parâmetros e F(y) é uma função distribuição de probabilidades conhecida. Com base nessa situação hipotética, julgue o item a seguir.
Considerando o modelo II, com n suficientemente grande e
!$ F(x)={e^x \over (1+e^x)} !$
como sendo a função de distribuição da logística, então a aproximação linear induzida nesse modelo por F(x) tem a forma
!$ ln \left ( {r_i/n \over 1 - r_i /n} \right ) = \alpha + \beta x_i + u_i !$
em que cada ui tem distribuição normal e variância igual a
!$ [n \pi _i (1- \pi _i)] ^{-1} !$
Provas
Caderno Container