Foram encontradas 566 questões.
Os seguintes gráficos correspondem a determinada série temporal e foram obtidos em uma análise exploratória antes de ajustar um modelo de previsão:
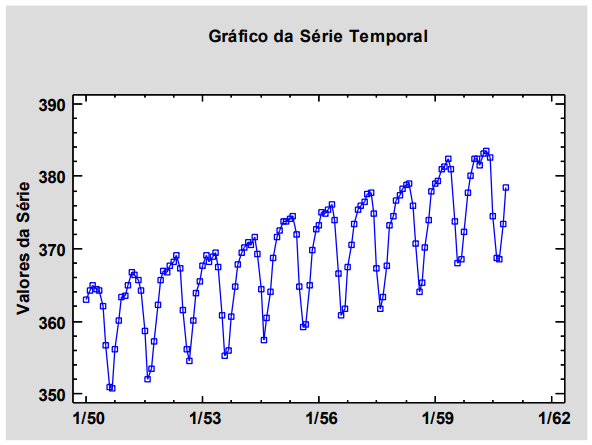
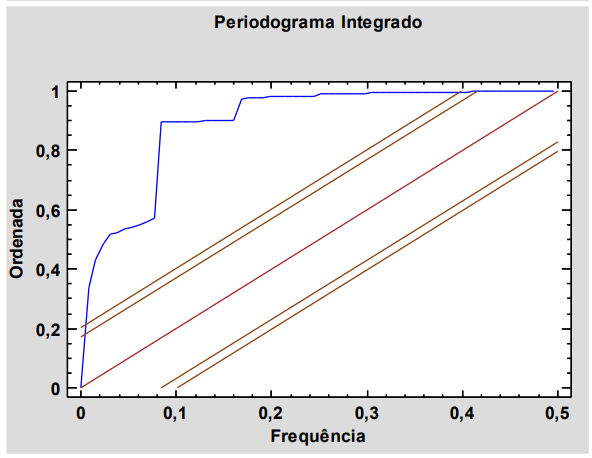
Observando os gráficos, é correto afirmar que
Provas
Seja a amostra aleatória de tamanho pequeno [X1, X2, ... , X10] de uma variável aleatória X com distribuição de probabilidade normal com média \( \mu \) e variância \( \sigma^2 \), então, as estatísticas \( { \large \bar{x} - \mu \over ^\sigma/_ \sqrt{10}}, { \large \bar{x} - \mu \over ^s/_ \sqrt{10}}, { \large x - \mu \over \sigma} \) e \( { \large x - \mu \over s} \) têm quais distribuições, respectivamente?
Provas
Provas
Em uma amostra aleatória com n = 25, observações da variável aleatória X que representam uma característica quantitativa foram obtidas por um estatístico que precisa estimar a média \( \mu \) e o desvio -padrão \( \sigma \) da população (distribuição) de onde a amostra foi tomada por intervalo de nível 95% de confiança. A análise dos dados forneceu os seguintes resultados: média amostral \( \bar{x} = 21,980 \)e desvio- padrão amostral s = 2,11877. O teste de Shapiro- Wilk, para verificar a Normalidade dos dados, resultou em W = 0,972867 e valor-p p = 0,721053; o escore t24,0975 = 2,0639 e os escores \( X_{24;0975}^2 \).
Então, é correto afirmar que os intervalos de confiança para a média \( \mu \) e o desvio- padrão \( \sigma \) são, respectivamente,
Provas
Se a variável aleatória X tem distribuição normal com média \( \mu \) e variância \( \sigma^2 \), ou seja, \( X\,\sim\,N ( \mu, \sigma^2), s^2 = { \large \sum_{i=1}^n ( x_i - \bar{x})^2 \over n-1} \) (variância amostral) é a estimativa de \( \sigma^2 \) com base em uma amostra com n observações, [x1, x2, .... , xn]. Assim, a variável \( T = { \large X - \mu \over s} \) tem distribuição t de Student com n – 1 graus de liberdade, ou seja, \( T\,\sim\, t_{n-1} \). Nesse caso, sabendo que \( P (T \le -2) = 0,031973 \), é correto afirmar que
Provas
Um estatístico conduziu um experimento para verificar se existem diferenças estatisticamente significativas entre os resultados quantitativos de três procedimentos aplicados em amostras independentes. Os resultados obtidos com o experimento são:
Tabela da Análise da Variância – ANOVA
|
Fonte de Variação |
Soma de Quadrados | G.L |
Quadrado Médio |
Razão F | Valor-p p |
|
Entre grupos |
1071,67 | 2 | 535,833 | 117,62 | 0,0000 |
|
Dentro dos grupos |
123,0 | 27 | 4,5556 | ||
|
Total (Corr.) |
1194,67 | 29 |
Teste de Levene para hipótese de variâncias
iguais
| Estatística do Teste | Valor -p p | |
| Lavena | 0,589852 | 0,5614 |
Teste de Normalidade para os resíduos da ANOVA
| Teste | Estatística do Teste | Valor -p p |
| Shapiro-Wilk W | 0,985139 | 0,939533 |
Teste de Kruskal-Wallis para hipótese de
medianas iguais
|
Tamanho da amostra |
Rank Médio | |
| Procedimento 1 | 10 | 5,95 |
|
Procedimento 2 |
10 | 15,05 |
|
Procedimento 3 |
10 | 25,5 |
Estatística do Teste = 24,8078 Valor-p p = 0,0000041025
Então, é correto afirmar, em relação ao nível de significância de 5%, que
Provas
Provas
A Razão das Chances é definida pela razão entre a probabilidade de sucesso e a probabilidade de insucesso, ou seja, . Então, assumindo \( y = \beta_0 + \beta_1 X_1 + \cdots + \beta_{p-1} X_{p-1} = \underline{x}' \underline{ \beta} \), tem- se no Modelo Logístico \( p = p ( \underline{x}) = p(X_1, X_2, \cdots, X_{p-1}) = { \large e^y \over e^y +1} = { \large 1 \over 1 +e^{-y}}= { \large 1 \over 1+ e^{ - \underline{x}' \underline{ \beta}}} \) . Portanto, a Razão das Chances no Modelo Logístico é
Provas
O estatístico que trata da análise de dados referentes à Justiça Federal necessita conduzir um estudo que requer informações sobre determinada característica quantitativa, X, dos processados em determinada Vara Federal. Um dos objetivos é construir um intervalo de 95% de confiança para o valor médio da característica quantitativa do grupo de processados, com erro de amostragem ou precisão de 0,5\( \sigma \), meio desvio- padrão. Ele tomou, então, uma amostra aleatória piloto de tamanho n0 = 5 que forneceu as seguintes estatísticas amostrais, média e variância, para a característica: \( \bar{x}_0 = 127,6 \) e \( S_0^2 = 1290,8 \) A respeito das informações anteriores, sabe-se que é possível assumir o modelo de distribuição normal para a característica quantitativa do grupo de processados, que é finito com N = 2000 indivíduos e com variância desconhecida. Assim, conhecendo o escore da distribuição t de t4(0,975) = 2,78, é correto afirmar que o tamanho definitivo da amostra n é
Provas
- AmostragemTipos de AmostragemAmostragem aleatória simples
- Estatística DescritivaMedidas de Dispersão
O estatístico de uma Vara Federal necessita verificar se a idade média dos condenados por prevaricação e a dos condenados por corrupção passiva são iguais. Para isso tomou amostras aleatórias de tamanhos: n1 = 15 de condenados por prevaricação e n2 = 20 condenados por corrupção passiva. As amostras forneceram as estatísticas: média amostral \( \overline{x} \)1 = 25 anos e desvio-padrão amostral s1 = 2 anos do grupo da prevaricação e \( \overline{x} \)2 = 31 anos e desvio-padrão amostral s2 = 3,5 anos do grupo da corrupção passiva. Verificou-se, aplicando os testes, que as amostras eram provenientes de distribuição normal, mas com variâncias desconhecidas e diferentes. Então, foi aplicado o teste adequado à situação e obteve-se, para a estatística do teste, o valor
Provas
Caderno Container