Foram encontradas 32.190 questões.
O Código de Ética Profissional do Estatístico está estruturado em diversas Seções,
cada uma tratando de aspectos específicos da profissão. Sobre essas disposições, assinale a
alternativa INCORRETA.
Provas
Questão presente nas seguintes provas
Com base na Seção II do Código de Ética do Estatístico, Dos Deveres Do Estatístico,
analise as assertivas abaixo, assinalando V, se verdadeiras, ou F, se falsas.
( ) O estatístico deve guardar absoluto sigilo dos assuntos que chegam ao seu conhecimento em razão do exercício profissional.
( ) Quando atuar como perito ou auditor, o estatístico deve abster-se de emitir opiniões tendenciosas nos laudos que produzir.
( ) É dever do estatístico indicar o número de registro no CONRE e a respectiva região em laudos, relatórios técnicos e declarações que emitir.
( ) Fere a ética profissional assumir compromissos que excedam a capacidade legal, técnica, financeira, moral e física do estatístico.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
( ) O estatístico deve guardar absoluto sigilo dos assuntos que chegam ao seu conhecimento em razão do exercício profissional.
( ) Quando atuar como perito ou auditor, o estatístico deve abster-se de emitir opiniões tendenciosas nos laudos que produzir.
( ) É dever do estatístico indicar o número de registro no CONRE e a respectiva região em laudos, relatórios técnicos e declarações que emitir.
( ) Fere a ética profissional assumir compromissos que excedam a capacidade legal, técnica, financeira, moral e física do estatístico.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Provas
Questão presente nas seguintes provas
Um pesquisador deseja verificar se houve diferença na idade dos participantes entre
dois grupos (grupo A e grupo B). Para decidir se deve aplicar um teste paramétrico ou um teste não
paramétrico, ele precisa verificar a normalidade dos dados. No SPSS, considerando a versão 18 ou
superior, qual é a alternativa que melhor representa o caminho para realizar o teste de normalidade
(Kolmogorov-Smirnov e/ou Shapiro-Wilk), levando em conta o objetivo do pesquisador?
Provas
Questão presente nas seguintes provas
R, SPSS e SAS são programas desenvolvidos principalmente para manipulação,
análise e modelagem de dados estatísticos, amplamente utilizados em diferentes áreas do
conhecimento. Apesar de apresentarem sobreposição de funcionalidades, existem distinções quanto
ao grau de flexibilidade, capacidade de integração e suporte a análises específicas. Comparando R,
SAS e SPSS, analise as assertivas abaixo:
I. Por ser de código aberto, o R costuma receber novos métodos apenas depois que eles são implementados e validados em outros programas.
II. O SAS e o SPSS podem executar rotinas em R, oferecendo a opção de usar funções do R em seus próprios ambientes.
III. R é muito flexível no tipo de dados que pode analisar, enquanto SAS e SPSS exigem que os dados estejam organizados em conjuntos ditos “retangulares”.
IV. O SPSS utiliza principalmente duas janelas: o editor de dados (Data Editor) e o visualizador (Viewer). Um dos pontos fortes do SPSS é a possibilidade de executar a maioria das análises apenas com o uso do mouse, sem necessidade de codificação.
Quais estão corretas?
I. Por ser de código aberto, o R costuma receber novos métodos apenas depois que eles são implementados e validados em outros programas.
II. O SAS e o SPSS podem executar rotinas em R, oferecendo a opção de usar funções do R em seus próprios ambientes.
III. R é muito flexível no tipo de dados que pode analisar, enquanto SAS e SPSS exigem que os dados estejam organizados em conjuntos ditos “retangulares”.
IV. O SPSS utiliza principalmente duas janelas: o editor de dados (Data Editor) e o visualizador (Viewer). Um dos pontos fortes do SPSS é a possibilidade de executar a maioria das análises apenas com o uso do mouse, sem necessidade de codificação.
Quais estão corretas?
Provas
Questão presente nas seguintes provas
No SPSS, diferentes comandos do menu Analyze > Descriptive Statistics permitem
realizar análises descritivas e explorar relações entre variáveis. Com base nas funcionalidades desses
comandos, analise as assertivas abaixo e assinale V, se verdadeiras, ou F, se falsas.
( ) O comando Analyze (analisar) > Descriptive Statistics (estatística descritiva) > Frequencies (frequências) pode ser utilizado para realizar análise descritiva de variáveis quantitativas, apresentando medidas como média, mediana, moda, desvio-padrão, quartis e outras.
( ) O comando Analyze (analisar) > Descriptive Statistics (estatística descritiva) > Descriptives (descritivas) realiza uma análise descritiva completa de variáveis quantitativas, apresentando medidas como média, mediana, moda, desvio-padrão, quartis e outras.
( ) O comando Analyze (analisar) > Descriptive Statistics (estatística descritiva) > Crosstabs (tabelas cruzadas) permite analisar a relação entre variáveis categóricas, apresentando frequências, percentuais, testes de hipóteses e também a opção de gráficos de barras.
( ) O comando Analyze (análise) > Descriptive Statistics (estatística descritiva) > Explore (explorar), além da análise descritiva, também permite realizar uma diversidade de gráficos, entre eles: histograma, boxplot, gráfico de linhas, de barras, entre outros.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
( ) O comando Analyze (analisar) > Descriptive Statistics (estatística descritiva) > Frequencies (frequências) pode ser utilizado para realizar análise descritiva de variáveis quantitativas, apresentando medidas como média, mediana, moda, desvio-padrão, quartis e outras.
( ) O comando Analyze (analisar) > Descriptive Statistics (estatística descritiva) > Descriptives (descritivas) realiza uma análise descritiva completa de variáveis quantitativas, apresentando medidas como média, mediana, moda, desvio-padrão, quartis e outras.
( ) O comando Analyze (analisar) > Descriptive Statistics (estatística descritiva) > Crosstabs (tabelas cruzadas) permite analisar a relação entre variáveis categóricas, apresentando frequências, percentuais, testes de hipóteses e também a opção de gráficos de barras.
( ) O comando Analyze (análise) > Descriptive Statistics (estatística descritiva) > Explore (explorar), além da análise descritiva, também permite realizar uma diversidade de gráficos, entre eles: histograma, boxplot, gráfico de linhas, de barras, entre outros.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Provas
Questão presente nas seguintes provas
Conforme descrito e ilustrado por Guimarães e Hirakata (2012), em modelos
correlacionados é comum se observar um “efeito principal”, que é o efeito direto de uma variável
independente sobre a variável dependente e um “efeito de interação”, que é o efeito conjunto de duas
ou mais variáveis independentes sobre a variável dependente (Fonte: GUIMARÃES, Luciano Santos
Pinto; HIRAKATA, Vânia Naomi. Uso do modelo de equações de estimativas generalizadas na análise
de dados longitudinais. Revista HCPA, Porto Alegre, v. 32, n. 4, p. 503-511, 2012). Considerando um
exemplo genérico, onde se deseja avaliar o efeito do grupo (A ou B) e do tempo (pré, durante e pós
intervenção) na variável escore de ansiedade, relacione a Coluna 1 à Coluna 2, associando as
ilustrações gráficas abaixo aos seus respectivos efeitos.
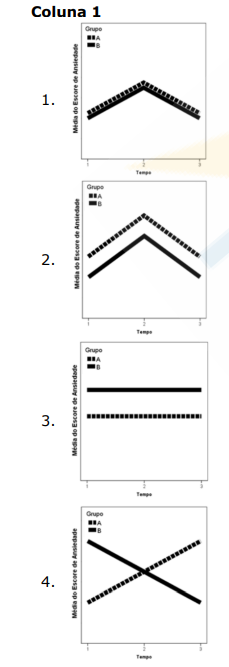
Coluna 2
( ) Efeito somente do tempo. ( ) Efeito somente do grupo. ( ) Efeito do grupo e do tempo. ( ) Efeito do grupo e do tempo com o efeito da interação.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Coluna 2
( ) Efeito somente do tempo. ( ) Efeito somente do grupo. ( ) Efeito do grupo e do tempo. ( ) Efeito do grupo e do tempo com o efeito da interação.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Provas
Questão presente nas seguintes provas
As Equações de Estimação Generalizadas (Generalized Estimating Equations – GEE)
foram desenvolvidas com o objetivo de fornecer estimativas consistentes e eficientes dos parâmetros
de modelos de regressão em situações em que os dados apresentam correlação. Esse método tem
sido amplamente empregado em análises de dados longitudinais e outros cenários com medidas
repetidas. Com base nos pressupostos e características dos modelos GEE, assinale a alternativa
correta.
Provas
Questão presente nas seguintes provas
Os Modelos de Equações de Estimação Generalizadas (Generalized Estimating
Equations – GEE) não exigem a suposição de esfericidade, pois permitem especificar diretamente a
estrutura de correlação entre medidas repetidas. A matriz de correlação de trabalho (working
correlation matrix) é uma estimativa dessa estrutura de dependência, utilizada para ajustar
corretamente os erros padrão e gerar estimativas robustas dos efeitos populacionais. No SPSS, ao
realizar uma análise GEE, é possível escolher entre cinco opções de matrizes de correlação para ajuste
dos modelos. Nesse contexto, relacione a Coluna 1 à Coluna 2, associando as seguintes matrizes às
suas respectivas características.
Coluna 1
1. Independente. 2. AR-1 (Autoregressive de 1ª ordem). 3. Troca (Exchangeable). 4. Dependente de ordem m. 5. Não estruturada.
Coluna 2
( ) Assume que a correlação entre quaisquer dois elementos é nula.
( ) Permite uma correlação diferente para cada par de medidas repetidas.
( ) Assume que cada medida repetida só é correlacionada com as m medições anteriores dentro do mesmo sujeito.
( ) Assume que todas as medidas dentro de um sujeito têm a mesma correlação m entre si (correlação homogênea).
( ) A correlação entre quaisquer dois elementos é igual a m para elementos adjacentes, m² para elementos separados por um terceiro e assim por diante, tal que –1 < m < 1.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Coluna 1
1. Independente. 2. AR-1 (Autoregressive de 1ª ordem). 3. Troca (Exchangeable). 4. Dependente de ordem m. 5. Não estruturada.
Coluna 2
( ) Assume que a correlação entre quaisquer dois elementos é nula.
( ) Permite uma correlação diferente para cada par de medidas repetidas.
( ) Assume que cada medida repetida só é correlacionada com as m medições anteriores dentro do mesmo sujeito.
( ) Assume que todas as medidas dentro de um sujeito têm a mesma correlação m entre si (correlação homogênea).
( ) A correlação entre quaisquer dois elementos é igual a m para elementos adjacentes, m² para elementos separados por um terceiro e assim por diante, tal que –1 < m < 1.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Provas
Questão presente nas seguintes provas
Um estudo clínico tem como objetivo avaliar o efeito de uma intervenção cirúrgica
sobre o peso corporal, verificando se a cirurgia resulta em uma redução significativa do peso em
comparação ao grupo que não foi submetido ao procedimento. Para isso, os pacientes foram divididos
em dois grupos: caso (submetidos à cirurgia) e controle (sem cirurgia). O peso corporal foi mensurado
em dois momentos: antes da cirurgia (peso basal) e três meses após a cirurgia (peso pós-cirurgia),
ou apenas após 3 meses, para o grupo controle. Considere os seguintes planejamentos estatísticos:
I. Plano 1 – ANCOVA (Análise de Covariância): Ajusta os valores de peso pós-cirurgia pelo peso basal, controlando eventuais diferenças iniciais entre os grupos. Nesse caso, o peso pós-cirurgia é a variável dependente, o grupo (caso versus controle) é o fator e o peso basal é incluído como covariável.
II. Plano 2 – GEE (Generalized Estimating Equations): Leva em conta a correlação entre medidas repetidas do mesmo indivíduo, permitindo estimar efeitos da cirurgia, do tempo e a variabilidade entre os pacientes. Considera as medidas repetidas de peso ao longo do tempo como variáveis dependentes, grupo (caso versus controle) e tempo (basal e pós-cirúrgico) como fatores.
III. Plano 3 – Test t pareado: Compara o peso basal e o peso pós-cirurgia dentro de cada grupo, separadamente. O peso é a variável dependente, o tempo (basal e pós-cirúrgico) é o fator de comparação.
Quais assertivas apresentam planejamentos que oferecem análises que permitem verificar estatisticamente se a cirurgia promove uma redução significativa no peso em comparação ao grupo controle?
I. Plano 1 – ANCOVA (Análise de Covariância): Ajusta os valores de peso pós-cirurgia pelo peso basal, controlando eventuais diferenças iniciais entre os grupos. Nesse caso, o peso pós-cirurgia é a variável dependente, o grupo (caso versus controle) é o fator e o peso basal é incluído como covariável.
II. Plano 2 – GEE (Generalized Estimating Equations): Leva em conta a correlação entre medidas repetidas do mesmo indivíduo, permitindo estimar efeitos da cirurgia, do tempo e a variabilidade entre os pacientes. Considera as medidas repetidas de peso ao longo do tempo como variáveis dependentes, grupo (caso versus controle) e tempo (basal e pós-cirúrgico) como fatores.
III. Plano 3 – Test t pareado: Compara o peso basal e o peso pós-cirurgia dentro de cada grupo, separadamente. O peso é a variável dependente, o tempo (basal e pós-cirúrgico) é o fator de comparação.
Quais assertivas apresentam planejamentos que oferecem análises que permitem verificar estatisticamente se a cirurgia promove uma redução significativa no peso em comparação ao grupo controle?
Provas
Questão presente nas seguintes provas
Estudo sobre Diabetes Tipo 2: Um pesquisador busca identificar os fatores associados à
probabilidade de um indivíduo desenvolver diabetes tipo 2. Para isso, foram coletados
dados de 200 participantes e ajustado um modelo de regressão logística binária no software
SPSS, considerando as seguintes variáveis explicativas:
• Idade (em anos): variável quantitativa contínua.
• Sexo (masculino/feminino): variável categórica com o masculino definido como
categoria de referência.
O resultado da análise no SPSS apresentou o seguinte output:
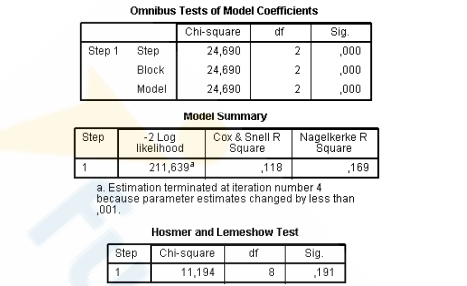
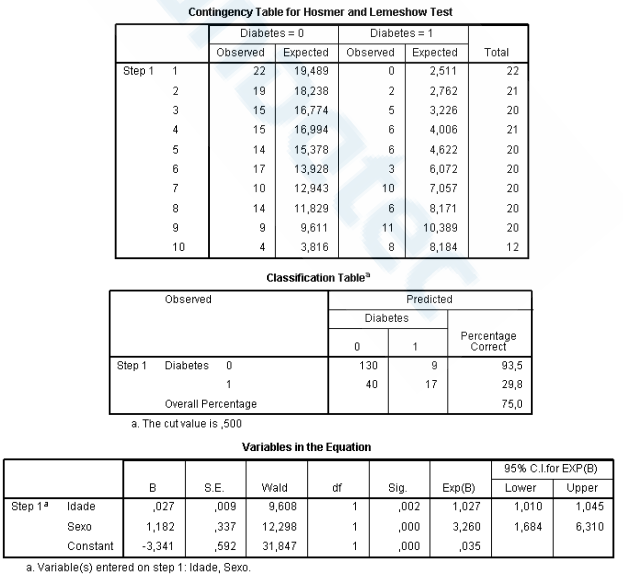
O _____________________ é utilizado para avaliar o ajuste global de um modelo de regressão logística, comparando os valores observados e previstos da variável dependente. A interpretação é direta: _______ indica um _____ ajuste. O teste é fácil de interpretar, amplamente usado em artigos científicos e fornece uma visão global do ajuste do modelo, mas tem limitações: em amostras grandes, pode detectar diferenças muito pequenas (excesso de sensibilidade) e, em amostras pequenas, pode não identificar problemas de ajuste, sendo recomendado combiná-lo com outras métricas e a análise de resíduos.
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
Provas
Questão presente nas seguintes provas
Cadernos
Caderno Container